

Editor’s note: This article was updated on September 20.
***
When the STAR*D study was launched more than two decades ago, the NIMH investigators promised that the results would be rapidly disseminated and used to guide clinical care. This was the “largest and longest study ever done to evaluate depression treatment,” the NIMH noted, and most important, it would be conducted in “real-world” patients. Various studies had found that 60% to 90% of real-world patients couldn’t participate in industry trials of antidepressants because of exclusionary criteria.
The STAR*D investigators wrote: “Given the dearth of controlled data [in real-world patient groups], results should have substantial public health and scientific significance, since they are obtained in representative participant groups/settings, using clinical management tools that can easily be applied in daily practice.”
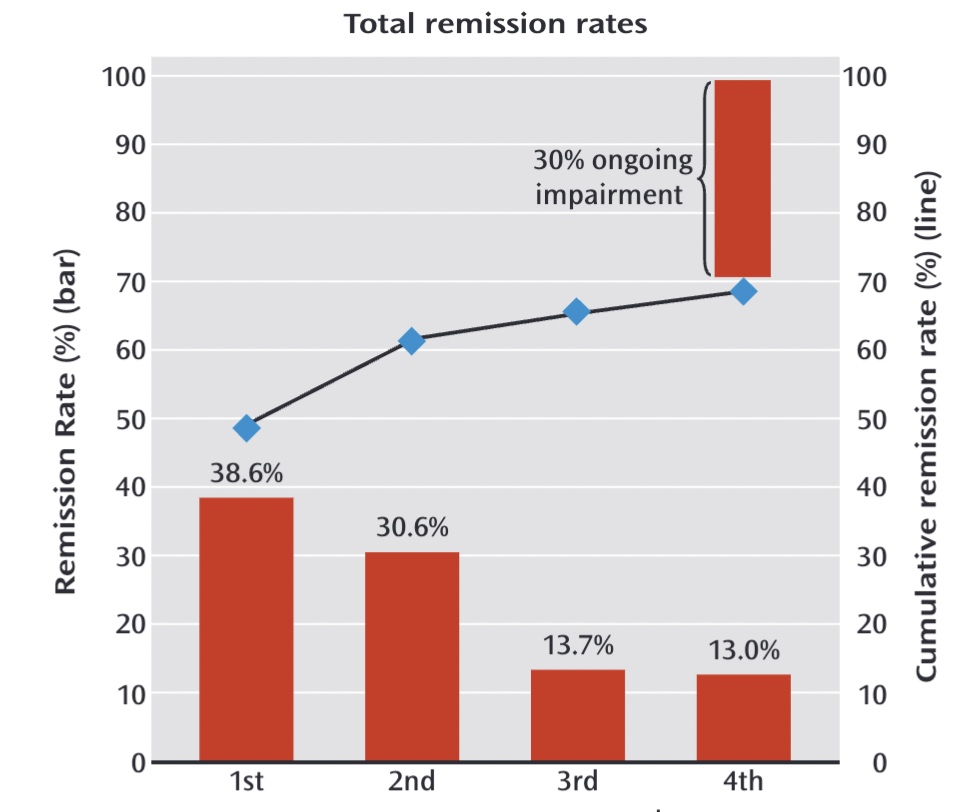
In 2006, they published three accounts of STAR*D results, and the NIMH, in its November press release, trumpeted the good news. “Over the course of all four levels, almost 70 percent of those who didn’t withdraw from the study became symptom-free,” the NIMH informed the public. Here is a graphic from a subsequent published review, titled “What Does STAR*D Teach Us”, that charts that path to wellness:
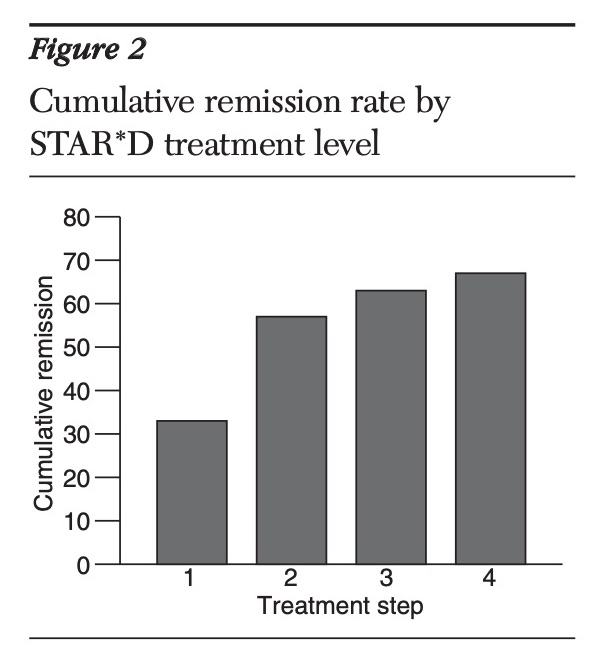
This became the finding that the media highlighted. The largest and longest study of antidepressants in real-world patients had found that the drugs worked. In the STAR*D study, The New Yorker reported in 2010, there was a “sixty-seven-percent effectiveness rate for antidepressant medication, far better than the rate achieved by a placebo.”
That happened to be the same year that psychologist Ed Pigott and colleagues published their deconstruction of the STAR*D trial. Pigott had filed a Freedom of Information Act request to obtain the STAR*D protocol and other key documents, and once he and his collaborators had the protocol, they were able to identify the various ways the NIMH investigators had deviated from the protocol to inflate the remission rate. They published patient data that showed if the protocol had been followed, the cumulative remission would have been 38%. The STAR*D investigators had also failed to report the stay-well rate at the end of one year, but Pigott and colleagues found that outcome hidden in a confusing graphic that the STAR*D investigators had published. Only 3% of the 4041 patients who entered the trial had remitted and then stayed well and in the trial to its end.
The protocol violations and publication of a fabricated “principal outcome”—the 67% cumulative remission rate—are evidence of scientific misconduct that rises to the level of fraud. Yet, as Pigott and colleagues have published their papers deconstructing the study, the NIMH investigators have never uttered a peep in protest. They have remained silent, and this was the case when Pigott and colleagues, in August of this year, published their latest paper in BMJ Open. In it, they analyzed patient-level data from the trial and detailed, once again, the protocol violations used to inflate the results. As BMJ Open wrote in the Rapid Responses section of the online article, “we invited the authors of the STAR*D study to provide a response to this article, but they declined.”
In fact, the one time a STAR*D investigator was prompted to respond, he confirmed that the 3% stay-well rate that Pigott and colleagues had published was accurate. While major newspapers have steadfastly ignored Pigott’s findings, after Pigott and colleagues published their 2010 article, Medscape Medical News turned to STAR*D investigator Maurizio Fava for a comment. Could this 3% figure be right? “I think their analysis is reasonable and not incompatible with what we had reported,” Fava said.
That was 13 years ago. The protocol violations, which are understood to be a form of scientific misconduct, had been revealed. The inflation of remission rates and the hiding of the astoundingly low stay-well rate had been revealed. In 2011, Mad in America published two blogs by Ed Pigott detailing the scientific misconduct and put documents online that provided proof of that misconduct. In 2015, Lisa Cosgrove and I—relying on Pigott’s published work and the documents he had made available—published a detailed account of the scientific misconduct in our book Psychiatry Under the Influence. The fraud was out there for all to see.
Pigott and colleagues subsequently obtained patient-level data through the “Restoring Invisible and Abandoned Trials” initiative (RIAT), and their analysis has confirmed the accuracy of their earlier sleuthing, when they used the protocol to deconstruct the published data. Thus, the documentation of the scientific misconduct by Pigott and colleagues has gone through two stages, the first enabled by their examination of the protocol and other trial-planning documents, and the second by their analysis of patient-level data.
Yet, there has been no public acknowledgement by the American Psychiatric Association (APA) of this scientific misconduct. There has been no call by the APA—or academic psychiatrists in the United States—to retract the studies that reported the inflated remission rates. There has been no censure of the STAR*D investigators for their scientific misconduct. Instead, they have, for the most part, retained their status as leaders in the field.
Thus, given the documented record of scientific misconduct, in the largest and most important trial of antidepressants ever conducted, there is only one conclusion to draw: In American psychiatry, scientific misconduct is an accepted practice.
This presents a challenge to the American citizenry. If psychiatry will not police its own research, then it is up to the public to make the fraud known, and to demand that the paper published in the American Journal of Psychiatry, which told of a 67% cumulative remission rate, be withdrawn. As STAR*D was designed to guide clinical care, it is of great public health importance that this be done.
An Intent to Deceive
The World Association of Medical Editors lists seven categories of scientific misconduct. Two in particular apply to this case:
- “Falsification of data, ranging from fabrication to deceptive selective reporting of findings and omission of conflicting data, or willful suppression and/or distortion of data.”
- “Violation of general research practices” which include “deceptive statistical or analytical manipulations, or improper reporting of results.”
The essential element in scientific misconduct is this: it does not result from honest mistakes, but rather is born from an “intent to deceive.”
In this instance, once Pigott and colleagues identified the deviations from the protocol present in the STAR*D reports, the STAR*D investigators’ “intent to deceive” was evident. By putting the protocol and other key documents up on Mad in America, Pigott made it possible for the scientific community to see for themselves the deception.
Their recent RIAT publication makes it possible to put together a precise numerical accounting of how the STAR*D investigators’ research misconduct, which unfolded step by step as they published three articles in 2006, served to inflate the reported remission rate. This MIA Report lays out that chronology of deceit. Indeed, readers might think of this MIA Report as a presentation to a jury. Does the evidence show that the STAR*D’s summary finding of a 67% cumulative remission rate was a fabrication, with this research misconduct born from a desire to preserve societal belief in the effectiveness of antidepressants?
The Study Protocol
According to the STAR*D protocol, patients enrolled into the study would need to be at least “moderately depressed,” with a score of 14 or higher on the Hamilton Depression Rating Scale (also known as HAM-D). They would be treated with citalopram (Celexa) at their baseline visit, and then, during the next 12 weeks, they would have five clinical visits. At each one, a coordinator would assess their symptoms using a tool known as the Quick Inventory of Depressive Symptomatology (QIDS-C). As this study was meant to mimic real-world care, physicians would use the QIDS data to help determine whether the citalopram dosage should be altered, and whether to prescribe other “non-study” medications, such as drugs for sleep, anxiety, or for the side effects caused by citalopram.
At each clinic visit, patients would also self-report their symptoms using this same measuring stick (QIDS-SR). The QIDS instrument had been developed by the STAR*D investigators, and they wanted to see whether the self-rated scores were consistent with the QIDS scores assessed by clinicians.
At the end of the treatment period, independent “Research Outcome Assessors” (ROAs) would assess the patients’ symptoms using both the HAM-D17 and the “Inventory of Depressive Symptomatology” scale (IDS-C30). The primary outcome was remission of symptoms, which was defined as a HAM-D score ≤7. The protocol explicitly stated:
“The research evaluation of effectiveness will rest on the HAM-D obtained, not by the clinician or clinical research coordinator, but by telephone interviews with the ROAs.”
And:
“Research outcomes assessments are distinguished from assessments conducted at clinic visits. The latter are designed to collect information that guides clinicians in the implementation of the treatment protocol. Research outcomes are not collected at the clinic.”
During this exit assessment, patients would also self-report their outcomes via an “interactive voice recording” system (IVR) using the QIDS questionnaire. This would be done “to determine how this method performed compared to the above two gold standards.” The protocol further stated:
“Comparing the IDS-C30 collected by the ROA and the QIDS16, collected by IVR, allows us to determine the degree to which a briefer symptom rating obtained by IVR can be substituted for a clinician rating. If this briefer rating can substitute for a clinician rating, the dissemination and implementation of STAR*D findings is made easier. Thus, the inclusion of QIDS16 by IVR is aimed at methodological improvements.”
After the first 12-week trial with citalopram, patients who hadn’t remitted were encouraged to enter a second “treatment step,” which would involve either switching to another antidepressant or adding another antidepressant to citalopram. Patients who failed to remit during this second step of treatment could then move on to a third “treatment step” (where they would be offered a new treatment mix), and those who failed to remit in step 3 would then get one final chance to remit. In each instance, the HAM-D, administered by a Research Outcome Assessor, would be used to determine whether a patient’s depression had remitted. At the end of the four steps, the STAR*D investigators would publish the cumulative remission rate, which they predicted would be 74%.
Patients who remitted at the end of any of the four steps were urged to participate in a year-long maintenance study to assess rates of relapse and recurrence for those maintained on antidepressants. The existing literature, the protocol stated, suggested that a “worst case” scenario was that 30% of remitted patients maintained on antidepressants “experience a depressive breakthrough within five years.” Yet, it was possible that real-world relapse rates might be higher.
“How common are relapses during continued antidepressant treatment in ‘real-world’ clinical practice?” the STAR*D investigators asked. “How long [are remitted patients] able to stay well?”
In sum, the protocol stated:
- Patients had to have a HAM-D score of 14 or higher to be eligible for the trial.
- The primary outcome would be an HAM-D assessment of symptoms administered by a Research Outcome Assessor at the end of the treatment period. Remission was defined as a HAM-D score of 7 or less.
- The secondary outcome would be an IDS-C30 assessment of symptoms administered by a Research Outcomes Assessor at the end of the treatment period.
- The QIDS-C would be administered at clinic visits to guide treatment decisions, such as increasing drug dosages. Patients would also self report their symptoms on the QIDS scale (QIDS-SR) to see if their scores matched up with the clinicians’ numbers. The two QIDS evaluations during clinic visits would not be used to assess study outcomes.
- The QIDS-SR administered by IVR at the end of treatment was for the purpose of seeing whether using this automated questionnaire, which took only six minutes, could replace clinician-administered scales to guide clinical care once STAR*D findings were published. It was not to be used to assess study outcomes.
- Relapse and stay-well rates would be published at the end of the one-year follow-up.
While the protocol was silent on how drop-outs would be counted, a 2004 article by the STAR*D investigators on the study’s “rationale and design” stated that patients with missing HAM-D scores at the end of each treatment step were “assumed not to have had a remission.”
Thus, the STAR*D documents were clear: those who dropped out during a treatment step without returning for an exit HAM-D assessment would be counted as non-remitters.
The Published Results
Step 1 outcomes
In January of 2006, the STAR*D investigators reported results from the first stage of treatment. Although 4,041 patients had been enrolled in the study, there were only 2,876 “evaluable” patients. The non-evaluable group (N=1,165) was composed of 607 patients who had a baseline HAM-D score of less than 14 and thus weren’t eligible for the study; 324 patients who had never been given a baseline HAM-D score; and 234 who failed to return after their initial baseline visit. Seven hundred ninety patients remitted during stage one, with their HAM-D scores dropping to 7 or less. The STAR*D investigators reported a HAM-D remission rate of 28% (790/2,876).
At first glance, this appeared to be a careful reporting of outcomes. However, there were two elements discordant with the protocol.
As Trivedi and colleagues noted in their “statistical analysis” section, patients were designated as “not achieving remission” when their exit HAM-D score was missing. In addition, they noted that “intolerance was defined a priori as either leaving treatment before 4 weeks or leaving at or after 4 weeks with intolerance as the identified reason.”
Thus, by both of these standards, the 234 patients who had failed to return after their baseline visit, when they were first prescribed Celexa, should have been counted as treatment failures rather than as non-evaluable patients. They were “intolerant “of the drug and had left the trial without an exit HAM-D score. If the STAR*D investigators had adhered to this element of their study plan, the number of evaluable patients would have been 3,110, which would have lowered the reported remission rate to 25% (790/3,110).
The second discordant element in this first publication tells more clearly of an “intent to deceive.” In their summary of results, they wrote:
“Remission was defined as an exit score of ≤7 on the 17-item Hamilton Depression Rating Scale (HAM-D) (primary outcome) or a score of ≤5 on the 16-item Quick Inventory of Depressive Symptomatology, Self-Report (QIDS-SR) (secondary outcome).”
They were now presenting QIDS-SR as a secondary outcome measure, even though the protocol explicitly stated that the secondary outcome measure would be an IDS-C30 score administered by a Research Outcome Assessor. Moreover, they were now reporting remission using the QIDS-SR score at the patient’s “last treatment visit,” even though the protocol explicitly stated that “research outcomes are not collected at the clinic.”
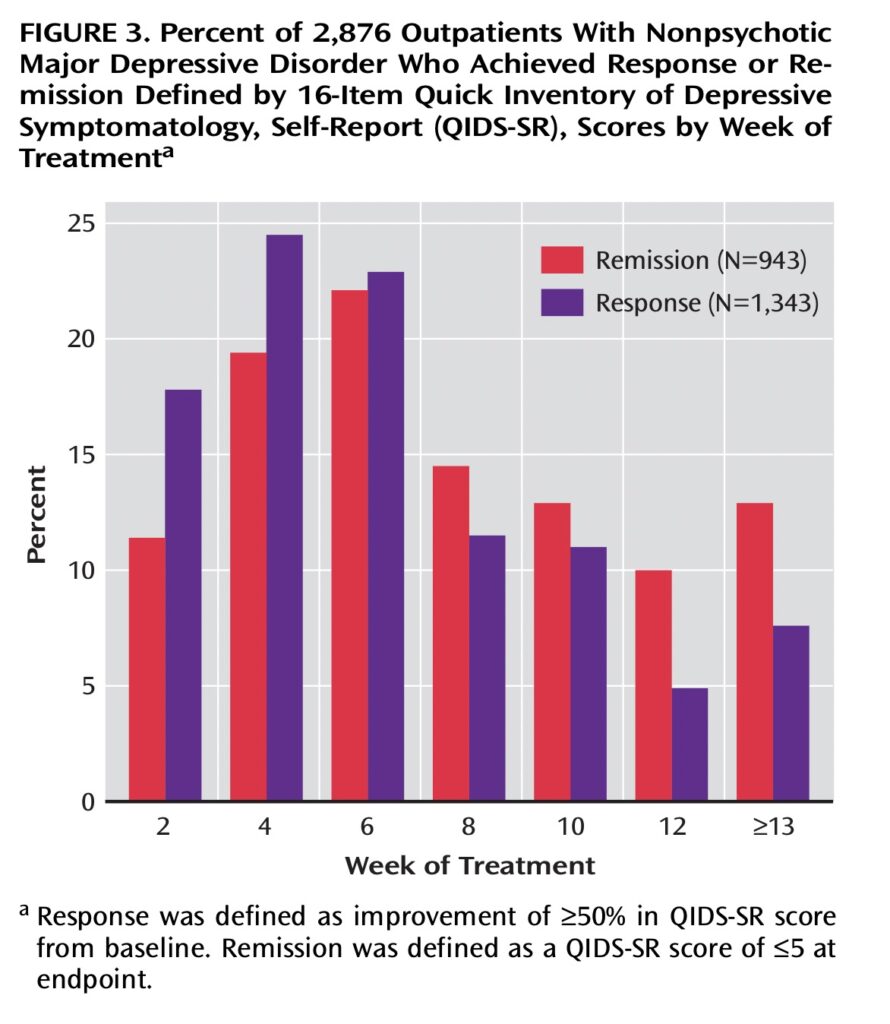
This switch to a QIDS-SR score from the clinic made it possible to count those who had no exit HAM-D score as remitters if their last in-clinic QIDS-SR score was five or less. This deviation from the protocol added 153 to their remitted count, such that on the QIDS-SR scale, 33% were said to achieve remission (943/2,876).
The STAR*D investigators even published a graphic of remission rates with the QIDS-SR, setting the stage for it to be presented, when the cumulative remission rate was announced, as the primary method for assessing effectiveness outcomes.
 Step 2 outcomes
Step 2 outcomes
Rush, et al. “Bupropion-SR, sertraline, or venlafaxine-XR after failure of SSRIs for depression.” NEJM 354 (2006): 1231-42. Also: Trivedi, et al. “Medication augmentation after the failure of SSRIs for depression.” NEJM 354 (2006): 1243-1252.
Two months later, the STAR*D investigators published two articles detailing remission rates for those who had failed to remit on citalopram and had entered the second treatment step (N=1,439).
One publication told of patients who had been withdrawn from citalopram and then randomized to either bupropion, sertraline, or venlafaxine. There were 729 patients so treated in step 2, and the remission rate was 21% on the HAM-D scale and 26% on the QIDS-SR scale. The investigators concluded that “after unsuccessful treatment, approximately one in four patients had a remission of symptoms after switching to another antidepressant.” That conclusion presented the QIDS-SR as the preferred scale for assessing remission.
The second publication told of remission rates for 565 patients treated with citalopram augmented by either bupropion or buspirone. The remission rate was 30% using HAM-D, and 36% using QIDS-SR. The investigators concluded that these two remission rates “were not significantly different,” yet another comment designed to legitimize reporting remission rates with QIDS.
There were two other deviations from the protocol in these reports on step 2 outcomes, although neither was easily discovered by reading the articles. The first was that the 931 patients cited as being “unevaluable” in the step 1 report, either because they had a baseline HRSD score less than 14 (607 patients) or no baseline score at all (324), were now being included in calculations of remitted patients. This could be seen in a graphic in Rush’s article, which stated that of the 4,041 enrolled into the trial, by the start of second step 1,127 had dropped out, 1,475 had moved into the one-year follow-up, and 1,439 had entered step 2. The 931 patients were now simply flowing into one of those three categories.
Here is the flow chart from the Rush paper that shows this fact:
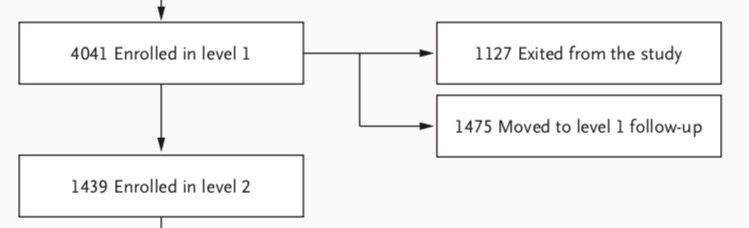
The re-characterization of the 931 patients as evaluable patients could be expected, of course, to markedly inflate cumulative remission rates. Not only were 607 not depressed enough to enter the study, but Pigott and colleagues, with their access to patient-level data, determined that 99 in this group had baseline HAM-D scores below 8. They met criteria for remission before they had been given their first dose of citalopram.
The second deviation was that patients who, at a clinic visit, scored as remitted on the QIDS-SR and sustained that remission for “at least 2 weeks,” could now be counted as having remitted and “move to follow-up.” Depressive symptoms are known to wax and wane, and with this new laxer standard, patients were being given multiple chances to be counted as “remitted” during any treatment step, and doing so using a self-report scale that they had filled out many times.
Final report on outcomes
In November 2006, the STAR*D investigators provided a comprehensive report on outcomes from both the acute and maintenance phases of the study. The protocol deviations, and thus the intent to deceive, are on full display in this paper.
Acute outcomes
Their reported remission rate of 67% relied on three deviations from the protocol, and a fourth “theoretical” calculation that transformed 606 drop-outs into imaginary remitters.
However, the patient numbers involved in the protocol deviations can seem confusing for this reason: in the summary paper, the count of evaluable patients has once again changed. The step 1 report told of 2,876 evaluable patients. The step 2 report added the 931 patients without a qualifying baseline HAM-D score back into the mix, which seemingly produced a total of 3,807 evaluable patients. But the final summary paper tells of 3,671 evaluable patients.
So where did this drop of 136 in the number of evaluable patients come from? In the step 1 report, the Star*D investigator stated there were 234 patients, out of the entering group of 4,041 patients, who didn’t return for a second visit and thus weren’t included in the evaluable group. In this summary paper, the STAR*D authors state there are 370 in this group. They provide no explanation for why this “did not return” number increased by 136 patients. (See footnote at end of this report for two possibilities.)
As for the 3,671 evaluable patients, the paper states that this group is composed of the 2,876 evaluable patients listed in the step 1 report, plus participants whose baseline HAM-D score was less than 14. The STAR*D authors do not explain why they are including patients who were not depressed enough to meet inclusion criteria in their count of evaluable patients. Nor do they state, in this summary report, how many are in this group. They also don’t mention their inclusion of patients who lacked a baseline HAM-D score.
As such, what is evident in this paper is that numbers are once again being jiggled. However, if the reader does the arithmetic, it becomes apparent that the count of 3,671 evaluable patients consists of the 2,876 patients deemed evaluable in the step 1 report, plus 795 patients who lacked a qualifying HAM-D score (out of 931 initially stated to be in this group). What the STAR*D authors did in this final report—for reasons unknown—is remove 136 from the group of 931 who lacked a qualifying HAM-D score and added them to the “didn’t show up for a second clinic visit” group.
While the patient count numbers have changed, it is still possible to provide a precise count, based on the new numbers in the final summary report, of how all three protocol deviations served the purpose of inflating the remission rate, and did so in one of two ways: either increasing the number of remitted patients, or decreasing the number of evaluable patients.
- Categorizing early dropouts as non-evaluable patients
The step 1 report listed 234 participants who had baselines scores of 14 or higher who didn’t return for a “post baseline” visit. As noted above, the protocol called for these patients to be chalked up as treatment failures. In their summary report, the STAR*D investigators added 136 to this count of non-evaluable patients, a change that further lowers the denominator in their calculation of a cumulative remission rate (remitters/evaluable patients).
2. Including ineligible patients in their count of remitted patients
The step 1 report excluded 931 patients whose baseline HAM-D scores were either less than 14 (607 patients) or were missing (324 patients). The final summary report includes 795 participants who lacked a qualifying HAM-D score, and as will be seen below, this group of 795 patients, who didn’t meet inclusion criteria, added 570 to the tally of remitted patients.
3. Switching Outcome Measures
The STAR*D investigators did not report HAM-D remission rates. Instead, they only reported remission rates based on QIDS-SR scores obtained during clinic visits. They justified doing so by declaring that “QIDS-SR and HRSD17 outcomes are highly related,” and that QIDS-SR “paper and pencil scores” collected at clinic visits were “virtually interchangeable” with scores “obtained from the interactive voice response system.” The protocol, of course, had stated:
-
-
- that the HAM-D was to be the primary measure of remission outcomes
- that QIDS was not to be used for this purpose
- that symptom assessments made during clinic visits were not to be used for research purposes
-
The justification that the STAR*D investigators gave for reporting only QIDS-SR scores suggested there was an equivalency between HAM-D and QIDS, when, in fact, the use of QIDS-SR regularly produced higher remission rates. The statement presented a false equivalency to readers.
With these protocol deviations fueling their calculations, the STAR*D investigators reported the following remission rates for each of the four treatment steps.
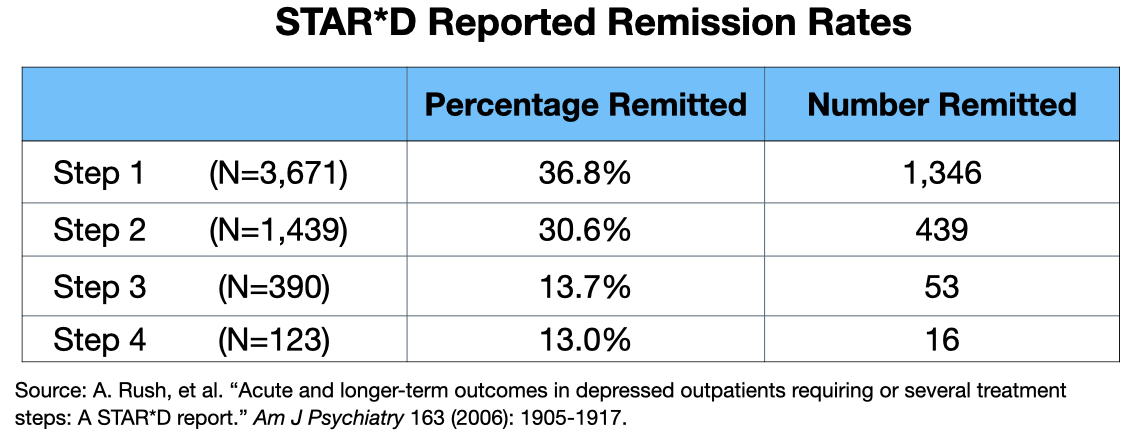
Thus, the cumulative remission rate at the end of four steps was said to be 51% (1,854/3,671).
In their recent reanalysis, Pigott and colleagues reported what the remission rates would have been if the protocol had been followed. First, the evaluable group should have been 3,110 patients (4,041 minus the 931 patients who didn’t have a baseline HAM-D score, or didn’t have a HAM-D score of 14 or higher). Second, HAM-D scores should have been used to define remission. Here is the data:
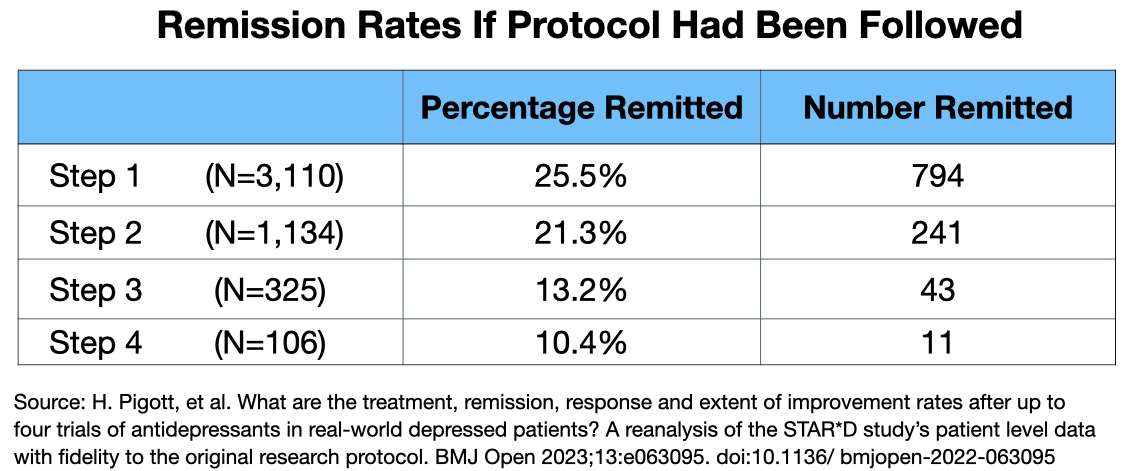
Thus, if the protocol had been followed, the cumulative remission rated at the end of four steps would have been 35% (1,089/3,110). The protocol deviations added 765 remitters to the “got well” camp.
Pigott’s 2023 report also makes it possible to identify the precise number of added remissions that came from including the 931 ineligible patients in their reports, and from switching to QIDs as the primary outcome measure.
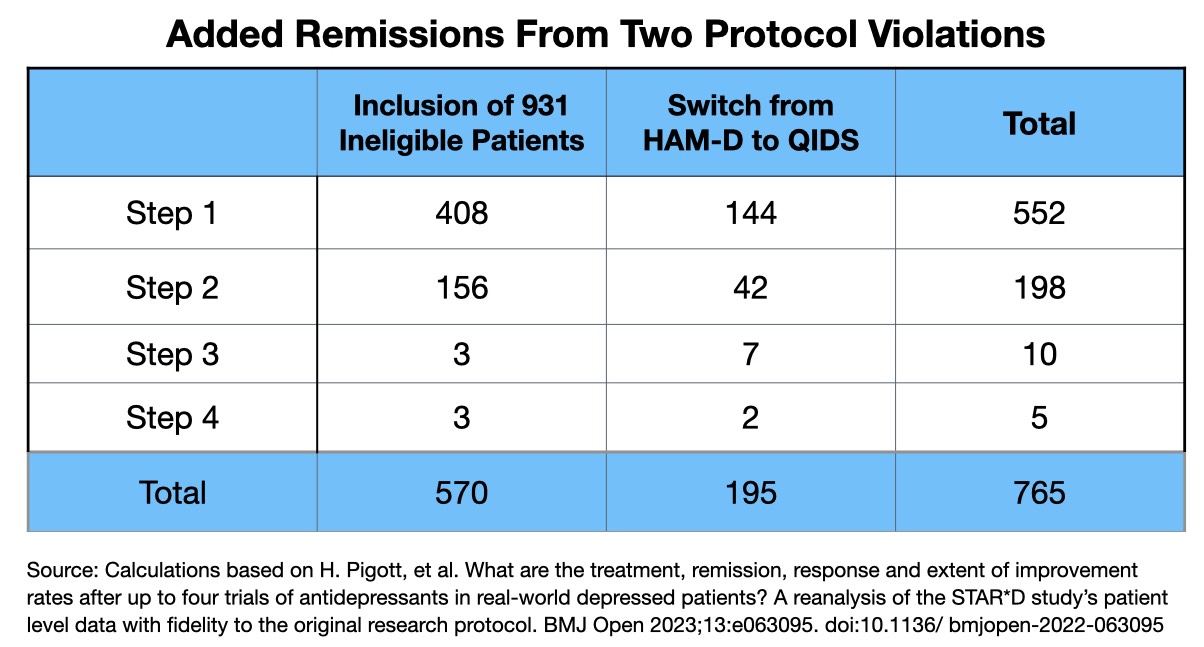
Even after these machinations, the STAR*D investigators still needed a boost if they were going to get close to their predicted get-well rate of 74%. To do so, they imagined that if the drop-outs had stayed in the study through all four steps of the study and remitted at the same rate as those who did stay to the end, then another 606 patients would have remitted. And voila, this produced a remission rate of 67% (2,460/3,671).
This theoretical calculation, as absurd as it was from a research standpoint, also violated the protocol. Those who dropped out without an exit HAM-D score less than 8 were deemed to be non-remitters. This theoretical calculation transformed 606 treatment failures into treatment successes.
Here is the final tally of how the STAR*D investigators’ research misconduct transformed a 35% remission rate into one nearly double that:
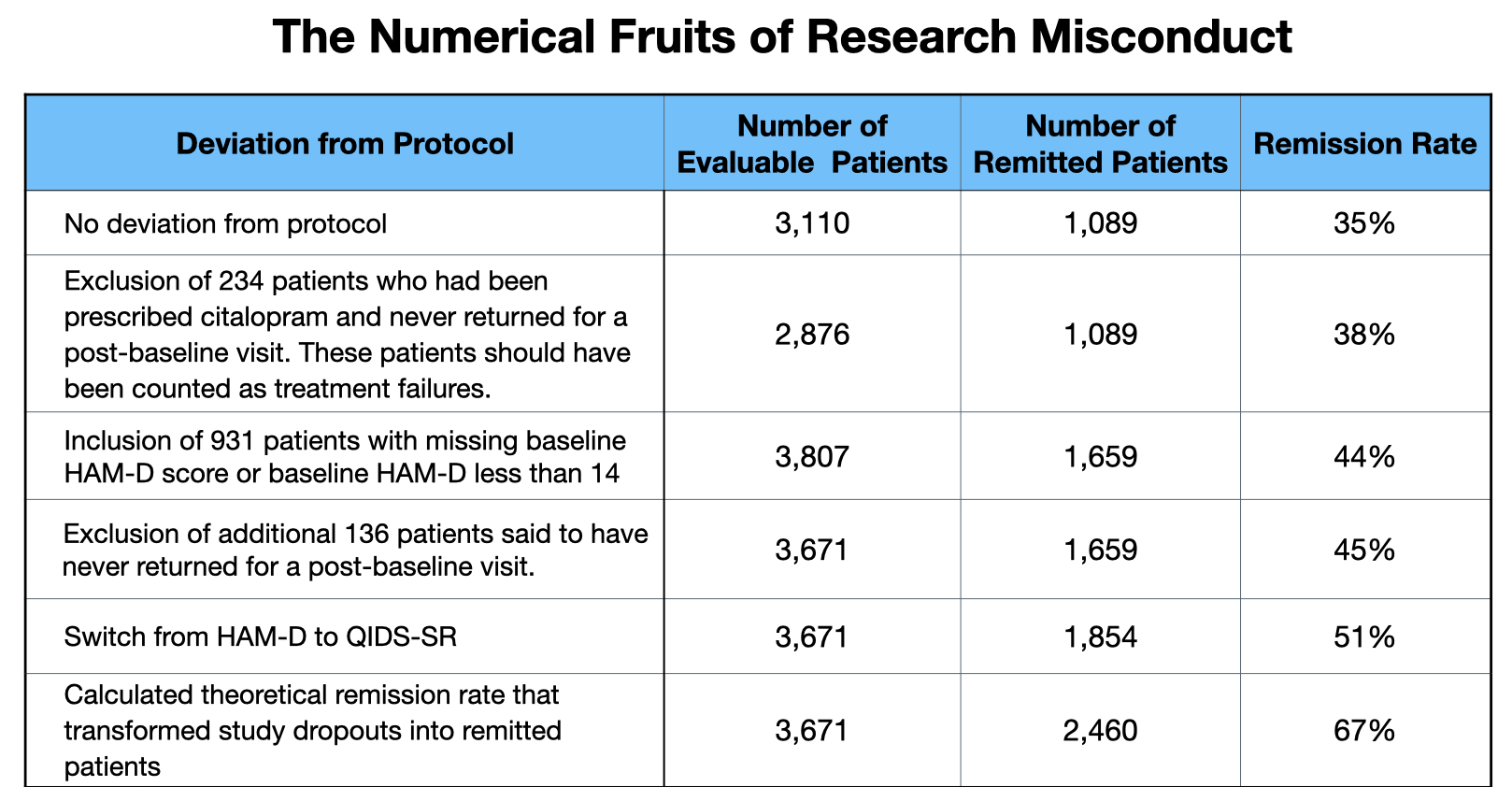
That is the account of research misconduct that took place in the acute phase of the STAR*D study. The abstract of the summary report told of an “overall cumulative remission rate,” without mentioning the theoretical element. As can be seen in this screenshot, the fabrication was presented as a bottom-line result:

This, in turn, became the fake number peddled to the public. For instance:
- The NIMH touted this number in a press release.
- The New Yorker, famed for its fact-checking, pointed to the 67% remission rate as evidence of the real-world effectiveness of antidepressants.
- Many subsequent articles in the research literature told of this outcome.
- A 2013 editorial in the American Journal of Psychiatry stated that in the STAR*D trial, “after four optimised, well-delivered treatments, approximately 70% of patients achieve remission.” A graphic depicted this stay-well rate:
More recently, after an article by Moncrieff and colleagues debunked, yet again, the chemical imbalance theory of depression, several major newspapers, including The New York Times, trotted out the 67% figure to reassure the public that they needn’t worry, antidepressants worked, and worked well.
One-year outcomes
There were 1,518 who entered the follow-up trial in remission. The protocol called for regular clinical visits during the year, during which their symptoms would be evaluated using QIDS-SR. Clinicians would use these self-report scores to guide their clincal care: they could change medication dosages, prescribe other medications, and recommend psychotherapy to help the patients stay well. Every three months their symptoms would be evaluated using the HAM-D. Relapse was defined as a HAM-D score of 14 or higher.
This was the larger question posed by STAR*D: What percentage of depressed patients treated with antidepressants remitted and stayed well? Yet, in the discussion section of their final report, the STAR*D investigators devoted only two short paragraphs to the one-year results. They did not report relapse rates, but rather simply wrote that “relapse rates were higher for those who entered follow-up after more treatment steps.”
Table five in the report provided the relapse rate statistics: 33.5% for the step 1 remitters, 47.4% for step 2, 42.9% for step 3, and 50% for step 4. At least at first glance, this suggested that perhaps 60% of the 1,518 patients had stayed well during the one-year maintenance study.
However, missing from the discussion and the relapse table was any mention of dropouts. How many had stayed in the trial to the one-year end?
There was a second graphic that appeared to provide information regarding “relapse rates” over the 12-month period. But without an explanation for the data in the graphic, it was impossible to decipher its meaning. Here it is:
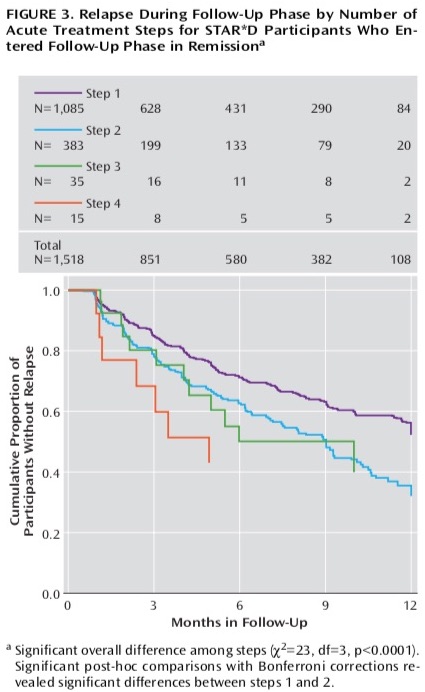
Once Pigott launched his sleuthing efforts, he was able to figure it out. The numbers in the top part of the graphic told of how many remitted patients remained well and in the trial at three months, six months, nine months and one year. In other words, the top part of this graphic provided a running account of relapses plus dropouts. This is where the drop-outs lay hidden.
Before Pigott published his finding, he checked with the STAR*D biostatistician, Stephen Wisniewski, to make sure he was reading the graphic right. Wisniewski replied:
“Two things can happen during the course of follow-up that can impact on the size of the sample being analyzed. One is the event, in this case, relapse, occurring. The other is drop out. So the N’s over time represent that size of the population that is remaining in the sample (that is, has not dropped out or relapsed at an earlier time).”
Here, then, was the one-year result that the STAR*D investigators declined to make clear. Of the 1,518 remitted patients who entered the follow-up, only 108 patients remained well and in the trial at the end of 12 months. The other 1,410 patients either relapsed (439) or dropped out (971).
Pigott and colleagues, when they published their 2010 deconstruction of the STAR*D study, summed up the one-year results in this way: Of 4,041 patients who entered the study, only 108 remitted and then stayed well and in the study to its one-year end. That was a documented get-well and stay-well rate of 3%.
Improper Reporting of One-Year Results
The World Association of Medical Editors lists “improper reporting of results” as research misconduct. The hiding of the dismal long-term results fits into that definition of misconduct.
In the protocol, the STAR*D researchers stated they would determine the stay-well rate at the end of one year. However, they didn’t discuss this figure in their published report of the one-year outcomes, and to MIA’s knowledge, none of the STAR*D investigators has subsequently written about it. The 3% number isn’t to be found in psychiatric textbooks, and again, to the best of MIA’s knowledge, no major U.S. newspaper has ever published this result. The only acknowledgement by a STAR*D investigator of this dismal outcome came when Medscape News asked Maurizio Fava about Pigott’s finding, and he acknowledged that it wasn’t “incompatible” with what they had reported.
As such, the STAR*D investigators have mostly kept it hidden from the public and their own profession, and it likely would never have surfaced had it not been for Ed Pigott’s obsession with fleshing out the true results from the “largest and longest trial of antidepressants ever conducted.”
Indeed, in 2009, NIMH director Thomas Insel stated that “at the end of 12 months, with up to four treatment steps, roughly 70% of participants were in remission.” He was now informing the public that 70% of the 4,041 patients who entered the study got well and stayed well, a statement that exemplifies the grand scale of the STAR*D fraud. Seventy percent versus a reality of 3%—those are the bottom-line numbers for the public to remember when it judges whether, in the reporting of outcomes in the STAR*D study, there is evidence of an “intent to deceive.”
Institutional Corruption
In Psychiatry Under the Influence, Lisa Cosgrove and I wrote about the STAR*D trial as a notable example of “institutional corruption.” There were two “economies of influence” driving this corruption: psychiatry’s guild interests, and the extensive financial ties that the STAR*D investigators had to pharmaceutical companies.
The American Psychiatric Association, which is best understood as a trade association that promotes the financial and professional interests of its members, has long touted antidepressants as an effective and safe treatment. After Prozac was brought to market in 1988, the APA, together with the makers of antidepressants, informed the public that major depression was a brain disease, and that the drugs fixed a chemical imbalance in the brain. The prescribing of these drugs took off in the 1990s, and has continued to climb ever since, such that today more than one in eight American adults takes an antidepressant every day.
The STAR*D results, if they had been accurately reported, would have derailed that societal belief. If the public had been told that in this NIMH study, which had been conducted in real-world patients, only 35% remitted, even after four treatment steps, and that only 3% remitted and were still well at the end of one year, then prescribing of these drugs—and societal demand for these drugs—surely would have plummeted. The STAR*D investigators, through their protocol deviations and their imagined remissions in patients that had dropped out, plus their hiding of the one-year results, turned the study into a story of the efficacy of these drugs. They were, in a business sense, protecting one of their primary “products.”
In addition, through their research misconduct, they were protecting the public image of their profession. The 67% remission rate told of skillful psychiatrists who, by trying various combinations of antidepressants and other drugs, eventually helped two-thirds of all patients become “symptom free.” The remitted patients were apparently completely well.
Even though STAR*D was funded by the NIMH, the corrupting influence of pharmaceutical money was still present in this study. The STAR*D investigators had numerous financial ties to the manufacturers of antidepressants. Here is a graphic that Lisa Cosgrove and I published in Psychiatry Under the Influence, which counted the number of such ties the various investigators had to pharmaceutical companies.
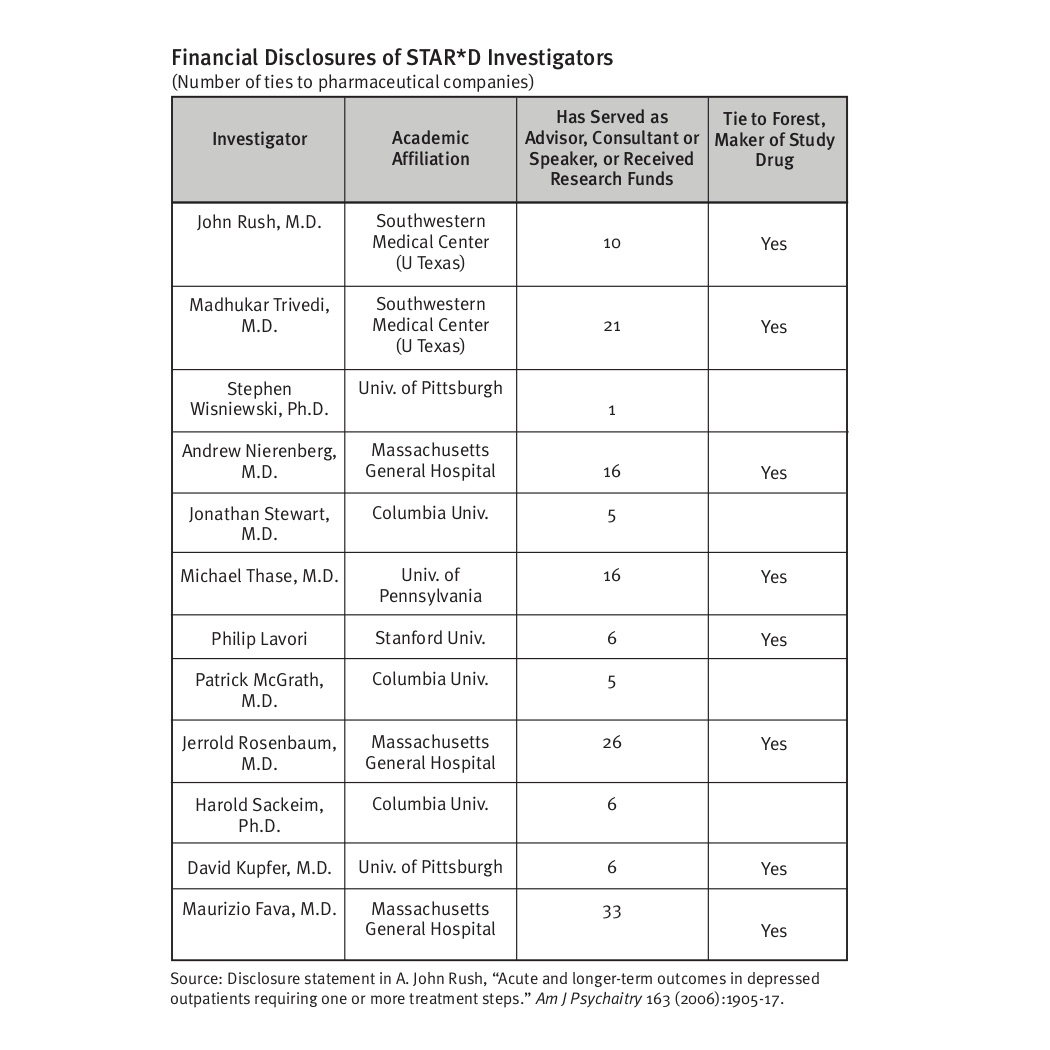
In total, the 12 STAR*D investigators had 151 ties to pharmaceutical companies. Eight of the 12 had ties to Forest, the manufacturer of citalopram.
The drug companies that sold antidepressants, of course, would not have been pleased if their key opinion leaders published results from a NIMH trial that told of real-world outcomes so much worse than outcomes from industry-funded trials of their drugs. The real-world efficacy that emerged in the STAR*D trial belied the advertisements that told of highly effective drugs that could make depression miraculously lift.
Thus, the poisoned fruit of institutional corruption: newspapers still today point to the 67% remission rate as evidence of the efficacy of antidepressants, while most of the public—and prescribers of these drugs—remain unaware of the true results.
The Harm Done
The articles published by Pigott and colleagues since 2010 have provided a record of the scientific misconduct of the STAR*D investigators. This MIA Report simply presents a chronology of the fraud, and, relying on their work, a numerical accounting of how each element of research misconduct boosted remission rates. The purpose of this MIA Report is to make clear the “intent to deceive” that was present in the STAR*D investigators’ deviations from the protocol, their publication of a fraudulent cumulative remission rate, and their hiding of the one-year outcome that told of a failure of this paradigm of care.
This research misconduct has done extraordinary harm to the American public, and, it can be argued, to the global public. As this was the study designed to assess outcomes in real-world patients and guide future clinical care, if the outcomes had been honestly reported, consistent with accepted scientific standards, the public would have had reason to question the effectiveness of antidepressants and thus, at the very least, been cautious about their use. But the fraud created a soundbite—a 67% remission rate in real-world patients—that provided reason for the public to believe in their effectiveness, and a soundbite for media to trot out when new questions were raised about this class of drugs.
This, of course, is fraud that violates informed consent principles in medicine. The NIMH and the STAR*D investigators, with their promotion of a false remission rate, were committing an act that, if a doctor knowingly misled his or her patient in this way, would constitute medical battery.
This cataloging of harm done extends to those who prescribe antidepressants. Primary care physicians, psychiatrists, and others in the mental health field who want to do right by their patients have been misled about their effectiveness in real-world patients by this fraud.
The harm also extends to psychiatry’s reputation with the public. The STAR*D scandal, as it becomes known, fuels the public criticism of psychiatry that the field so resents.
Yet, and this may seem counterintuitive, there is now an opportunity for psychiatry to grasp. The American Psychiatric Association, and the international community of psychiatrists, could take a great step forward in regaining public trust if they spoke out about the STAR*D fraud and requested a retraction of the published articles. Doing so would be an action that told of a profession’s commitment, as it moves forward, to uphold research standards, and to provide the public with an honest accounting of the “evidence base” for psychiatric drugs.
However, failing to do so will only deepen justified criticism of the field. It will be a continuance of the past 15 years, when psychiatry has shown, through its inaction, that research misconduct in this domain of medicine—misconduct that rises to the level of scientific fraud—is acceptable practice, even though it may do great harm.
A Public Petition to Retract the STAR*D Summary Article
As we believe this is a matter of great importance to public health, Mad in America has put up a petition on change.org urging the American Journal of Psychiatry to retract the November 2006 summary article of the STAR*D results. A 2011 article on the subject of retraction in a medical journal noted the following:
Articles may be retracted when their findings are no longer considered trustworthy due to scientific misconduct or error, they plagiarize previously published work, or they are found to violate ethical guidelines. . . Although retractions are relatively rare, the retraction process is essential for correcting the literature and maintaining trust in the scientific process.
In this case, the facts are clear: the 67% remission rate published in the American Journal of Psychiatry in November 2006 can no longer be “considered trustworthy due to scientific misconduct,” and that retraction of the article “is essential for correcting the literature and maintaining trust in the scientific process.” The article also noted that “there is no statute of limitation on retractions.”
Moreover, the World Association of Medical Editors, in its “Professional Code of Conduct,” specifically states that “editors should correct or retract publications as needed to ensure the integrity of the scientific record and pursue any allegations of misconduct relating to the research, the reviewer, or editor until the matter is resolved.”
And here is one final fact that makes the case for retraction. The NIMH’s November 2006 press release, which announced that “almost 70% of those who did not withdraw from the study became symptom free,” contains evidence that the NIMH itself, or at least its press office, was duped by its own investigators. Either that, or the NIMH silently countenanced the fraud.
First, it notes that of the 4,041 who entered the trial, “1,165 were excluded because they either did not meet the study requirements of having “at least moderate” depression (based on a rating scale used in the study) or they chose not to participate.” Thus, it stated, there were 2,871 “evaluable patients.” The NIMH press office either didn’t know that 931 patients who lacked a HAM-D baseline score that met eligibility criteria had been added back into the mix of remitted patients, or else it deliberately hid this fact from the public.
Second, the press release stated that the purpose of the QIDS-SR assessments during clinic visits was to inform ongoing care: “Patients were asked to self-rate their symptoms. The study demonstrated that most depressed patients can quickly and easily self-rate their symptoms and estimate their side effect burden in a very short time. Their doctors can rely on these self-rated tools for accurate and useful information to make informed judgments about treatment.” This, of course, was consistent with the protocol, that QIDs would be used for this purpose, but instead was the instrument that the STAR*D investigators used to report remission rates in their summary paper.
Here is Ed Pigott’s opinion on the call for retraction: “I started investigating STAR*D in 2006 and with colleagues have published six articles documenting significant scientific errors in the conduct and reporting of outcomes in the STAR*D trial. STAR*D’s summary article should clearly be retracted. This is perhaps best seen by the fact that its own authors lack the courage to defend it. By rights and the norms of ethical research practice, STAR*D authors should either defend their work and point out the errors in our reanalysis or issue corrections in the American Journal of Psychiatry and New England Journal of Medicine where they published their 7 main articles. What they can’t defend must be retracted.”
Our hope is that information about this Mad in America petition will circulate widely on social media, producing a public call for retraction that will grow too loud for the American Journal of Psychiatry to ignore. Indeed, the publication of the RIAT re-analysis of the STAR*D results in a prestigious medical journal presents a Rubicon moment for American psychiatry: either it retracts the paper that told of a fabricated outcome, or it admits to itself, and to the public, that scientific misconduct and misleading the public about research findings is accepted behavior in this field of medicine.
The petition can be signed here.
—–
Footnote: There are two possible explanations for the increase in the number of the 4,041 participants who were said to have failed to return for a second visit (from 234 in the step 1 report to 370 in the final summary). One possibility is that 136 of the 931 patients said to lack a qualifying HAM-D score never returned for a second visit, and thus in the summary report, they were added to this “didn’t return” group and removed from the 931 group, leaving 795 participants who lacked a qualifying HAM-D score included in the count of evaluable patients.
A second possibility can be found in the patient flow chart published in the step 1 report. Here it is:
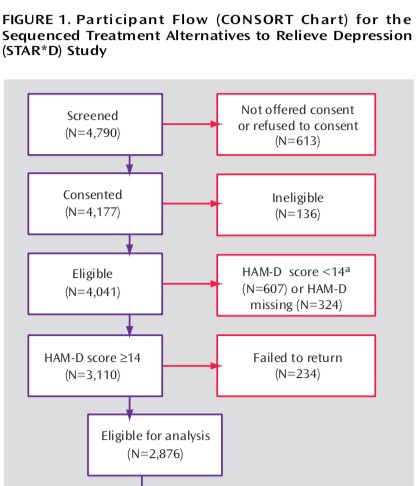
You can see here that there were 4,177 who consented to being in the study. Then 136 were deemed to be ineligible for some reason, and thus weren’t included in the count of 4,041 patients who entered the study. However, the 136 ineligible patients in the 4,177 count would have had a first screening visit, and once they were told they were ineligible, would not have returned for a second clinic visit. So the possibility here is that the STAR*D authors took this group of 136 ineligible patients, who never entered the study, and added them into the “did not return” group in order to further decrease the denominator in their final remission count.
Thus, there are two possibilities. The first tells of an extraordinary numerical coincidence. There were 136 patients who were declared ineligible before the study began, and a second, different group of 136 patients who lacked a qualifying HAM-D score, yet were allowed to enter the study but failed to return for a second clinic visit. The second possibility tells of falsification of data, a particularly egregious form of research misconduct.
As always by Robert Whitaker, an incredibly well-researched and well-articulated investigation. It’s striking, despite all that was already previously written about Star*D, to see the level of misconduct and deceit carried out by the investigators laid out in such astonishing detail. As you articulated, any movement towards psychiatry’s correcting the deceptions and falsities concerning the efficacy and safety of antidepressants occurs at a glacial pace – hopefully, this petition is the kindling that sparks a more sincere effort by the guild.
Report comment
none of thing which psychiatrists says are not true. so this is not also true. psychiatrists continuous lie. psychiatrists in turkey continuous help to nationalists and militarists. psychiatrists in turkey request to diagnose schizophrenia to three groups. psychiatrists in turkey diagnose schizophrenia to three groups
1.lgbti+
2.feminists
3.advocates of conscientious objection in military service
Report comment
It might seem off topic, but rereading your posts on other MIA articles I might have an insight.
Turkey seems to be a signatory of the Convention on the Rights of Persons with Disabilities. So, that opens the possibility that human rights abuses might be reversed or mitigated soliciting the help of the local or top turkish human rights comission.
In Mexico, just the fact that Mexico is a signatory allowed for the Mexican Supreme Court to abolish the “mental guardianshp” state. That is the loss of autonomy of decision that restrict the ability to live freely, to say no to treatment, etc. Just one case that reached the Supreme Court did a difference, there were several, but touched on different aspects, as far as I recall.
I am not advising, I had poor experiences, althoug mixed, with a local human rights comission, but if Turkey is a signatory that might provide a better way for redress human rights abuses than looking for a psychiatrist to reverse a diagnosis. Or to provide relief…
Just, this my advice, I think it is useful to read what are the limitations of the human rights comission when receving a complaint. Sometimes just signing a waiver might preclude the comission from intervening, and I have some evidence mental hospitals even forge those, they have cameras you know…
So best to be prepared to address concerns or objections that might cause a complaint to be dismissed. Reading the procedure for human rights comissions complaints is very usefull. Trying not to lie or misstate, that might get one in even hotter water.
And even if some comissions claim there is no need for a lawyer, given the procedure to investigate and reverse human rights abuses is adversarial, the human rights comission might not provide effective, efficacious legal advice when writing or fighting a complaint. Most of the time in my opinion the help of at least a human rights lawyer might make a significant difference.
There are those that work for free, but they are rare, I went without lawyer and got partial results at best. But still what I got in principle allowed me to take the fight further, even if time passed. But I think even at the human rights comission is best to have a lawyer commited to the cause instead of the profit.
In my experience even if human rights comissions sometimes work for the system, some even share the, to my mind, delusions of the practice of psychiatry, they are bound by rules and procedures as all bureaucrats are, so, it worked for me to be patient and try to ignore their ignorance and sometimes ill will. Not all wrokers for human rights comissions are like that, some in my case did a good work even if the head of the comission erased, apparently, all of the work of what appeared to me a really strong solid case. Such was for me.
I hope it helps, from my experience, learning about human rights abuses might provide more relief than going straight to the judiciary, which is, in my opinion, more likely to be true in countries that actually are signatories of several United Nations treaties than the US, which it is not. They only have civil rights 🙂 No pun or putoff intended.
That is based on the fact of the legal theory that international treaties have a law status equal or a little below the Constitution. That is the case of Mexico and it’s hotly debated, but it might be relevant for the case of Turkey.
That is: where in the preponderance of laws that start at the Constitution passes to the Law, to the regulation and ends in the procedure manual of a hospital, is the International Treaty signed by Turkey is to be located. Is it above the law that deprives the rights of people imputed with a mental illness? or is it below?.
That could provide an opening to fight the oppresion of an individual with apparently no other relief…
Regards. I feel for you…
PS: Reaching the Supreme Court anywhere in the world is a long shot, but hopping without being unrealistic might provide another insight that might provide relief. Arguing succesfully for why a complaint should be admited is a crucial step, and reading and learning about human rights in countries that are bound to follow those might open a way, maybe different, to get some air amid all the oppresion. Judiciously and with care. I live in Mexico you know, not a nice place.
And yeah!!!! off topic, but I think important, balance of interests, I did got to the top judiciary, I got a signed letter by the top Chief Justice on an maybe not maybe yes unrelated case. Just I don’t want to get hopes too high. I got lucky, amid all the persecution, so I try to share.
Report comment
The graph No. 3 is a really weird graph. If I add intuitively ALL the patients that achived response adds to around 99%.
If I add all the patients that achieved remission I get 101%.
Clearly adding both I get 200%.
So along the course of 0 to more than 13 weeks around 200% of patients or meassurements (!?) achieved either remission or response. Probably AND. Hum!?
Trying to give the benefit of the doubt to the researchers/publishers of the STAR*D it seems that at best 43% of the patients, not necesarily the same, achieved remission or response, only to loose most of that “improvement” at 12 weeks, to recover some after 13 weeks. Which is not a given.
And continuining my misplaced trust, at BEST, this remission or response is TRANSITORY and precisely peaks at the time psychiatrists claim antidepressants start kicking in.
Except… around 29% of the patients got remission or response at TWO weeks, too early to kick in, as per the psychiatrists rhetoric in the office.
And! 15% percent of patients, around a third of the peak “improvement” have such “improvement” at 12 weeks. Trying to keep in my mind that patients at 4 weeks peak improvement and patients at more than 13 weeks might or not be the same.
Relevant because “improvement” could oscilate, at a given point some might be improved, only for 2 weeks later or more not improvement, even worsened, and so forth, like a sinus wave with no real significant improvement over time, just on this Figure 3 graph.
A rollercoaster…. similar to the hypothesis about manic depresive disease, bipolar disease number 1 or 2, whatever…
Specially because worsening or deterioration is not in this graph. So what percentage of patients got WORSE along this curve?. Let alone how many got manic…
Reminding me, that they are not necessarily the same patients. Each patient just by the 200% patients sumation (area under the curveS) likely went into response or remission at least twice, to fall to an “improvement” rate of 15% at 12 weeks. And around 20% of either remission or response after 12 weeks.
That sounds to me like a transitory oscillating look better and possibly feel better measured with a close to random apparatus, i.e. cakcomamie measuring scales. That looks heckuba lot like what manic depressive disease was described when I was a medical student around 30yrs ago.
Gravely so since likely some of the “quitters” from the study probably got “manic”. Which given this is a controlled study most likely had no previous diagnosis of manic disease.
Report comment
From the second study phase, refered from Rush et al. from NEJM:
Funny, 1475 moved to follow up out of 4041 patients enrolled that moved to follow up is 36.5% which is neither the 13% remitted, not the 7% responsive, nor an addition of both at equal or more than 13 weeks, which is 20%.
And its not the 51% of 1475 of the 2876 reported in figure 3!?.
So some of these new 1475 apparently are not part of the 20% improved of ONLY 2876, as per the review, and were moved to follow up WITHOUT being either remitted nor improved at equal or more than 13 weeks. Apparently any meassurement at any point had an influence of calling patients responsive or remitted, regardless that latter they might not have qualified as such.
Trying to square the circle: some of the 1475 patients that entered the next follow up of the study might have gotten “cyclicaly” improved somehow, oddly, between the beyond 12 weeks assessment, whatever that was, and the phase 2 entry/enrollement… More cycles.
Report comment
“70%” vs. “3%,” efficacy for antidepressants? Wow, I’d call that psychiatric scientific “fraud.” And what is the historic normal recovery rate from “depression?”
Thank you so much, Mr. Whitaker, for all you’ve done to point out the harm done to those of us who were harmed by the psychiatric and psychological and mainstream medical industry’s – now claimed ignorance – of the common adverse and withdrawal effects of the dangerous, and deadly, “antidepressants.”
Especially given the reality that all MD’s were taught in med school, that both the antidepressants and antipsychotics can create “psychosis and hallucinations” – the positive symptoms of “schizophrenia” – via anticholinergic toxidrome poisoning.
https://en.wikipedia.org/wiki/Toxidrome
Report comment
“However, if the reader does the arithmetic, it becomes apparent…” I tried and I failed… miserably…
But 931 below 14pts + 324 missing is 1255 not 1127… And not 1255-136, which is 1119., which is how related to “didn’t show up for a second clinic visit”?.
I insist, 1346 remitted in step 1 of 4041 is 33.3%. And 1346 of 2876 is 46.8%. Neither 36.8%.
‘”They did not report relapse rates…”‘ thank you!. ‘“relapse rates were higher for those who entered follow-up after more treatment steps.”’ ohhh… hulk sad…
So speculating relapse rates might have stayed oscillating around the same level during the whole four phases, they were just lost, unmeassured, back to depression, or somehow non-complaint with the protocol design, beyond the non-compliance of the researchers.
And… 33.5%, 47.4%, 42.9% and 50% seems to me oscillating upwards. Not unlike old descriptions of manic depressive disease…
“it was impossible to decipher its meaning.” well, to me it basically says that during each step, from 1 to 4, around 40% to 50% of patients have relapsed or quitted, which is around TWICE those remited or responsive at least from step 1. And apparently at each of the other steps.
And from my experience, direct and par other providers, lost patients either got better, got complicated or got no improvement.
Given these patients were motivated to stay in the study given it was supposed to be a scientific study, guessing educatedly they were not improved. So the not remitted in the obscure survival curve gaph probably got no improvement or got complicated.
Report comment
As stated sounds like medical battery by proxy.
Report comment
So, apparently self reported improvement scales for depression top the HAM-D clinicians administered assesments in feeling better, and even then it oscillates back to relapse, withdrawal, or I speculate complications.
With a grain of salt: that sounds like a stimulant… not unlike coffee for some folks, that after a few hours of drinking it they feel more sleepy. And not much improved in cognitive tests after a sleepless night after drinking coffee.
Like the mythical awake drunk.
Except in 4 weeks, more or less, cycles, which is around twice the interval of measurement in the Figure 3 of step 1 graph, so that could cycle even faster. But oddly conspiranoically might be related to Nyquist’s number/frequency.
Which now that I reflect might imply an 8 week cycle, not a four weeks one. And looking at Figure 3 of step 1 at 8 weeks I see similar values as at 2 weeks. No score at 0 weeks is provided, a glaring omission on a second look.
And at 12 weeks the score is worse than at 2 weeks, so either at 0 or between 0 and minus 8 weeks the score could be actually higher than at 12 weeks. A potential decline in score AFTER treatment.
And caffeine has a half life in blood of around 1-2hrs, if I remember correctly. Although it does seem to cause “long term” adaptations/changes.
Report comment
Like the whole antidepressant treatment thing is a rollercoaster of “improvement” at 8 weeks intervals of a “new” medication, that requires adding or switching to another antidepressant to keep meassuring an “improvement” at some point. Go Fish! Catch up the remission or remitted score!
Trying to sum up Homer Simpson style: GWeee! GWeee!. So the psychiatrist or patient can record an improvement. To be lost after some weeks, but we can try another Gweee!…
So callous, so fraudulent, so shameless…
And so not really trying to meassure worsening nor deterioration, just “relapse”, even if transitory. Or worse yet MANIA/HYPOMANIA, even if, God hopes, transitory…
And transitory might not sound that bad, but that’s when bad outcomes like incarceration, involuntary hospitalization, homelessnes, divorce, AIDS, homicide or suicide happens…
So manic depressive look alike. Without me validating the label.
Report comment
Just a bunch of quotes from scientific abstracts:
“A great deal of evidence suggests that virtually all antidepressant treatments induce a dopaminergic behavioral supersensitivity.”
“This review aims to report the experimental evidence that led to the hypothesis that antidepressant-induced DA receptors dysregulation can be considered an animal model of bipolar disorder. ”
“Chronic antidepressant treatments enhance dopaminergic neurotransmission in the mesolimbic dopamine system.”
“We have demonstrated that 21 d administration of imipramine causes a behavioural syndrome similar to a cycle of bipolar disorder, i.e., a mania followed by a depression, in rats. Indeed, such treatment causes a behavioural supersensitivity to dopamine D2 receptor agonists associated with an increase sexual activity and aggressivity (mania).” with inability to enoy it [my comment].
So antidepressants neurochemically can cause not only bipolar, but psychosis…
WARNING:
Imipramine use for betwetting, i.e. enuresis is RECOMENDED by “NICE Clinical Guidelines, No. 111.” from 2010.
” Consider imipramine for children and young people with bedwetting who: have not responded to all other treatments and have been assessed by a healthcare professional with expertise in the management of bedwetting that has not responded to an alarm and/or desmopressin.[1.14.3]”
But hey! is not that bad!:
“15.2.8.6. Withdraw imipramine gradually when stopping treatment for bedwetting in children and young people.[1.14.6]”.
I guess there being no guidelines as to how safely withdraw from antidepressants in adults, let alone children, it should be A problem.
How many million children were exposed to imipramine since decades ago?. Could that explain beyond overdiagnosis the increase in number of children diagnosed as bipolar or with psychosis?.
Report comment
Beyond my tirades, I will really like if you could answer this:
Robert Whittaker, intruding with respect and admiration: What is the standard deviation at patient level data of at least the QIDs scale meassurements?. At least at 2 weeks intervals, preferable longer, shorter perhaps but maybe not available. A graph of variations along the 2 to 13 or more weeks would be ideal.
Superfantastic if such graph could be calculated for each step!. From 1 to 4!, among the remainers, “hulk sad”…
Please!? Kitty in boots face!?.
Because that would provide evidence or context to how accurate the meassurements are, whether the sample size was enough, whether the statistical significance reported is accurate and much more. And following the petition it could provide strength to the claim of scientific misconduct with intent to deceive, or mislead… or violation of generally accepted research practices.
And on third look at the graph, a telltale sign of bad science, in this case perhaps some form of improper callibration of meassurement is the lack of error bars at the top of each of the bars in the graph.
The mythical “no error bars” flaw…
That is not even acceptable I pressume in college.
Report comment
And with me begging grand license from readers/editors/contributors/moderators at MIA:
Let me guess! No such standard deviation in normal population has been INDEPENDENTLY accurately determined for any and all depression scales!. Yihaaa!
That would be a terrific graduation project! if not for the most likely probability that it would be unpublishable, even for a bachelor degree.
But!, it might get an IgNoble prize!. Given the QIDs are/is self administered.
Given the incentives, qualifications, blah blah blah.
In honor of Greta Thunberg, being angry is the thing we failed to do…
Report comment
All I have is rage and despair. Everything else was stolen.
Report comment
really you say very right. l also am feel same thing. l occasionally request to commit suicidie for escape from psychiatry because psychiatry condemn to live with family me. the purpose of psychiatry is to sell a drug and make a very money this way. psychiatry in turkey helps to nationalism and militarism.psychiatry in turkey is very hypocrite
Report comment
I’m sorry you are dealing with the same feelings, mura. I try to be grateful that I’m not currently being force-treated but it’s hard when it could happen again so easily.
I don’t know much about the situation in Turkey, but I’m going to read up on it. I know that psychiatry gets used for both capitalist and political purposes everywhere it has a stronghold (but health purposes, not so much.)
I wish things were different, for all of our sakes.
Report comment
there is a psychiatric association. the state in turkey founded an association to show psychiatry to the whole world that it defends human rights. the purpose of the state in turkey is covering up human rights violations by psychiatrists.
Report comment
The problem here is the initial premise that bad thinking can cause disease. It is an absurd notion. Depression’s collective symptoms represent human pheromone deficiency, that is easily remedied. 10mg p.o. of healthy adult male facial skin surface lipid pheromone (Nicholson, B. BJD 111(5):623-7) boosted bimonthly to semi-annually alleviates all symptoms of depression. Two precautions need to be taken. The 10mg of adult male face grease must have its volatile organic chemicals removed as they are emotionally toxic sentinel sub-pheromones that effectively protect the human pheromone from medical manipulation, and an ounce or two of wine should follow administration to prevent osculation partner jealousy.
This is, quite obviously, the eucharist or communion protocol of the Christian Church. Psychologists will be uncomfortable with this Jewish ritual, of course, but it does explain the rise of Christianity and the anecdotal effectiveness of the protocol. Unleavened bread is an excellent vehicle for pheromone transmission. Wine’s ethanol cuts the skin surface lipids to cleanse the mouth. Without the pheromone to detect, no jealousy arises in mouth-to-mouth kissing partners.
What is needed is to dismantle the NIH, replacing it with prizes for disease cures that recognize the importance of good “mental” health to America.
Report comment
I am not trying to comandeer the discussion, nor supress any part of it, even mine. Hopefully I’ll try for this to be my last comment on this.
I think the reluctance to withdraw the refered paper or set of papers might have more to do with violations to the research subjects that might require investigation by, guessing, the HHS or the DoJ.
Why? Because the prestige of the NIMH, the researchers, the publishers, the media that got deceived and retold a misstatement, the damage to the insulin for diabetes creed, etc., to my view is not enough to stop the withdrawal.
So, assuming I am right on the previous paragraph which is not a given then the case might be more severe. There might be corruption, pharma intromission, unacknowledged conflicts of interest, etc. The usual thing in the discourse of scientific misconduct that involves pharma and psychiatry in clinical research.
And precisely because the practice of psychiatry has a notorious track record of human rights violations and illegality as extensively documented here at MIA by a lot of harmed people then in a kind of preponderance of suspicion the deanonymized record of the research subjects might be the thing they are trying to protect, not the usuals of the two previous paragraphs of my, this post.
Data which I assume is in possession of the NIH, not behind a private corporation vault. Might be more accesible for a justice/administrative inquiry. Within the jurisdiction of the investigative body without much resistance otherwise.
I imagine that following the outcome of one violation, even just for reparations of harms, could lead to find out that harm to patient extended beyond the research setting. I extend if it were more than 1 research subject. Dozens? Hundreds?
And that could reveal officially, investigatively, in an administrative or judicial context a more severe damage by psychiatrical practice than psychiatrical publishing might suggest. And that is more dangerous than dealing with vanilla scientific misconduct, given precisely its prevalence, how common it is, and that might lead to stronger resistance to withdraw the papers.
And even papers withdrawn, just by the passing of time, the cause to investigate might have been made more difficult or even barred, just by the passage of time. Which is a recurrent theme in psychiatrical clinical practice even here at MIA testimonials, AFIU.
Report comment
I have signed the petition and hope many others do so as well. So important!
Report comment
Mr. Whitaker is a noble, relentless border collie with the mission of herding dangerous, infected sheep into an isolation pen…culled from the herd of (any) ethical medical scientists.
If this important article could be distilled into a 2-minute HuffPost piece, it could have a chance to reach folks who have been dangerously duped regarding these drugs.
Fit Bits, organic food sources, & work-outs-YES. Addictive, damaging, ineffective brain-drugs-YES!
WTF.
I’m not bright enough to fully grasp this important article but….my familiarity with the topic & ‘players’ causes a rise of bile in my throat….an “evidence-based”, “bio-centric”, “life-long” SYMPTOM of exposure to pharmaceutical manufacturers and their full array of apostles, all feasting on the trusting, the vulnerable, & the frightened.
Addiction to anti-depressants can result in an addict’s obedience to the prescriber. (the whole point)
Let’s ask the exploited targets (‘key opinion leaders’!) who are trying to withdraw….what THEY think.
Report comment
Krista, your idea of summarizing the fraud for a piece in the Huffington Post is a good idea. I’ll see what I can do in that regard.
Report comment
Es que quieren vender 100% medicamentos psiquiátricos. Esa es la única evidencia.
Report comment
Psychiatry isn’t science — it’s science FICTION.
Report comment
With all immodesty…to a Pulitzer nominee’s dedication & writing skills….from an admirer…make sure ‘amazing’ is used at least twice…with ‘devastating’ shoe-horned in there somewhere….because…HuffPost.
A tiny laugh about a deadly topic.
Report comment
3% stay-well rate but about a 50% chance of having serious problems withdrawing.
Maybe prescribes need to say that to anyone that wants them?
Report comment
Yeah, but who would want them if they actually told the truth about the drugs?
Report comment
I second Krista’s suggestion for a condensed presentation. In keeping with the statement that “it is up to the public to make the fraud known”, another format/route may be considered based on the HuffPo summary-to-be of the fraud.
Format: animation w/ narration following the HuffPo article
Route: social media e.g. YouTube, Twitter (pardon, “X”)
The format of a concise animated video presentation might be a far easier way for the layman to understand the fraudulent juggling of inclusion/exclusion criteria and also get a real handle on how the timing of protocol violations produced the desired “near 70%” mantra for public consumption.
The route not only resonates with the idea of empowering the public via a social network approach, but it also bears the possibility that the clip may go “viral”. If done with enough flair & creativity, I’d say there’s a fair chance for that to happen.
In my opinion the idea of condensing is great. With such an intricate case however, the resulting article, jam-packed with data and super condensed plot may not be as easily digested by the ppl you’re trying to reach. I’m also somewhat skeptical of said outlet’s willingness to publish such an article, but that’s beside the point here.
A visual presentation that integrates timeline, narration and depiction of the data all in one flow could be the way to remedy possible drawbacks of a text-only precipitate of a complex scientific fraud and thus successfully conquer way more hearts & minds than one could ever imagine.
Just sayin’ 😉
Cheers from Amsterdam (from someone with past research experience in longitudinal evaluation of psychiatric treatment in primary care settings, i.e. drug/CBT vs “usual care”)
Report comment
Mr. Ran,
“I’m also somewhat skeptical of said outlet’s willingness to publish such an article, but that’s beside the point here.”
I’m basing HuffPost’s erratic journalistic acceptance bar by the several Allen Frances-authored (on HuffPo) blatherings in service of his endless quest for legitimacy in a specialty field that rejects him-his ‘peers’ & the public-at-large, who are aware of his unsavory reputation.
Mr. Whitaker brings substance…science & math (numbers don’t lie-when the math is accurate!), as well as standing as a principled participant on a topic without conflict-of-intere$t.
Pharma/Psychiatry does not enrich him…something that will taint Frances to the grave, Duke University’s low standards notwithstanding.
Appealing to HP demographic; quickly absorbed, using ‘Gen’ vocabulary, presented as the corruption & danger to their zealously guarded health-physical and MENTAL-is the key. The headline language is critical to stop a swipe.
I learned as an artist and line cook…’You eat with your eyes’…is applicable across life.
As a skilled communicator, Mr. Whitaker can & will make an impact…another foot in the door.
Placement of the messaging is critical-Marketing 101. And repeat.
MIA is a valued forum…but is…more often than not, preaching to the converted…it has been critical to my recovery knowing there are others who ‘know what happens…really.’
I keep thinking THIS research will change things, THAT study will shock them, MONCRIEF-for God’s sake….but no.
‘We’ need to busta’ (bigger) move.
BTW-clinicians & psych literature repeat how they are eager to “Meet us (clients) where WE are”. It’s dangerous recruitment BS from them, but absolutely valid in marketing-selling ideas.
Whelp…the social media whale & all the attached remora fish…is the way in 2023.
Report comment
Krista, I love your comments, thank you very much!
“The credibility of any scientific paper is in inverse to the magnitude/momentum of the ego of the author/s,” where ego is defined as the unobserved mind – the thinking which is susceptible to fear and so which, when push comes to shove, as it does even in scientific and academic circles, of course, tends to put reputation, power, promotion, prospects and money ahead of any burning desire to reveal Truth. And which of us is yet fully immune to such thinking?
Krista, you know what they say, that “the obstacle is the way,” and that if this world were perfect, it wouldn’t be, and that endlessly perfectible – by each of us – is infinitely preferable to already “perfect” – for any of us?
But, hey, what do they know when, ultimately, no one can say why we are here?
It seemingly took many millennia of human (and other) evolution to bring us to where we are today. And we can trace several millennia during which male-
dominated societies have insisted that we are all flawed creatures – miscreants, sinners, mentally ill or with sick or disordered personalities.
In the name of God, of Goodness, we have taught our children to believe such damning lies and nonsense, and they, like us, have acted accordingly: “Give a dog a bad name and…”
I don’t know anyone who has contributed as much as Bob Whitaker or Eckhart Tolle to turning all that thinking around, but, assuming we are all equal, each as one infinite and immortal aspect of one At-Least-Infinitely Loving Intelligence, it cheers me greatly to believe that every single one of us can and must and will contribute as much and more…and to know that only for her with infinite patience can everything happen immediately. I don’t know if Confucius said that or that “Young man who fancy pretty nurse must be patient,” but I suspect he may have acknowledged that only foolishness and forgetfulness can keep us from laughing, or at least from feeling like it.
Well meaning clerics may have preached for millennia that there are saints and sinners, good gals and guys and bad gals and guys, and we may have believed them. And well meaning doctors may actually believe and preach much the same nowadays, and fool us, too.
When we all finally learn to stop pointing fingers at one another, perhaps then and only then can all our suffering and, with it psychopharmacology, be dissolved, or transmuted to joy?
“Who looks outside, dreams. Who looks within, awakens.” – Carl Jung.
It’s been said that what we do not transmute, we inevitably transmit, but perhaps we can at any moment create ever better new realities for everyone simply by adjusting our own attitudes – perhaps classical Newtonian physics does not “break down at quantum level,” but we live in an infinitude, at least, of parallel quantum universes, ultimately of our own choosing/creation, and which we can access once we can fully accept all we encounter in any one – universe OR person?
With great gratitude to you, Krista, to Bob and to all at MIA,
Tom.
“Beyond a wholesome discipline, be gentle with yourself. You are a child of the universe no less than the trees and the stars; you have a right to be here.
And whether or not it is clear to you, no doubt the universe is unfolding as it should.”
– from “Desiderata,” by Max Ehrmann, 1927.
Report comment
I wonder if the AMA, the ACP or the CEJA have commented on this scandal?
Perhaps they might like to sign that petition.
Best wishes, and thanks for inspired and inspiring reporting.
Tom.
Report comment
….or the FSMB and/or all US medical boards, certainly including any which supposedly oversee/s the actions of any responsible doctor members of the NIMH?
https://www.fsmb.org/about-fsmb/
Silence on the part of any relevant authority surely colludes, condones, conspires, corrupts and/or demonstrates how dangerous it may be for the public, jurors or judges to trust any expert medical opinion when it comes to condoning coercive psycho-pharmacology.
Who shall judge the judges, and whose opinions might judges trust? Perhaps more and more of those of the late (psychiatrists) Thomas Szasz and Loren Mosher?
http://www.narpa.org/reference/mosher#:~:text=Dear%20Rod%3A,from%20the%20American%20Psychopharmacological%20Association.
Thank you once again!
Best wishes, all!
Tom Kelly.
Report comment
Excellent and very exciting site. Love to watch. Keep Rocking.
Report comment
Excellent and very exciting site. Love to watch. Keep Rocking.
Report comment
Excellent and very exciting site. Love to watch. Keep Rocking.
Report comment
superb article by a superb investigator and fact-based journalist, Robert Whitaker.
Report comment