
On July 25, 2017, Fredrik Hieronymus et al published a meta-analysis in Molecular Psychiatry. The study is titled “Efficacy of selective serotonin reuptake inhibitors in the absence of side effects: a mega-analysis of citalopram and paroxetine in adult depression.” Elias Eriksson, PhD, Head of the Department of Pharmacology, University of Gothenburg, Sweden, is the principal author, but as Fredrik Hieronymus is the first author listed, I will refer to the article as Hieronymus et al.
Here’s the abstract:
“It has been suggested that the superiority of antidepressants over placebo in controlled trials is merely a consequence of side effects enhancing the expectation of improvement by making the patient realize that he/she is not on placebo. We explored this hypothesis in a patient-level post hoc-analysis including all industry-sponsored, Food and Drug Administration-registered placebo-controlled trials of citalopram or paroxetine in adult major depression that used the Hamilton Depression Rating Scale (HDRS) and included a week 6 symptom assessment (n = 15). The primary analyses, which compared completers on active treatment without early adverse events to completers on placebo (with or without adverse events) with respect to reduction in the HDRS depressed mood item showed larger symptom reduction in patients given active treatment, the effect sizes being 0.48 for citalopram and 0.33 for paroxetine. In actively treated subjects reporting early adverse events, who also outperformed those given placebo, the severity of the adverse events did not predict response. Several sensitivity analyses, for example, including (i) those using change of the sum of all HDRS-17 items as effect parameter, (ii) those excluding all subjects with adverse events (that is, also those on placebo) and (iii) those based on the intention-to-treat population, were all in line with the primary analyses. The finding that both paroxetine and citalopram are clearly superior to placebo also when not producing adverse events, as well as the lack of association between adverse event severity and response, argue against the theory that antidepressants outperform placebo solely or largely because of their side effects.”
The fact that antidepressants are only very marginally better than placebos is well-established. In addition, many authors have asserted that even this marginal superiority is an artifact. The reasoning goes like this: In order to prove that a drug is effective, the manufacturer has to prove, not only that it seems to help some people, but that on average it does better than a placebo. This is because placebos do seem to have a beneficial effect, especially in psychiatry. The placebo probably produces its effect by providing attention, raising hopes, etc.
So the manufacturer has to show that the pills (in this case, antidepressants) outperform a placebo. This is done by enrolling a large number of study participants, dividing them at random into two approximately equal groups, giving a placebo to one group, giving the active drug to the other group, and monitoring the outcome.
But — and this is critical — neither the participants, nor the evaluators who are rating them for change can know who has been given the drug and who has been given the placebo. Any such inkling would undermine the entire procedure.
Studies of this sort are called randomized, double-blind trials, and great pains are taken to ensure that participants and raters remain “blind.”
And here’s the problem: people who have been randomly assigned to take the active drug often come to realize this, because the drug has more detectable effects than a few grams of sugar, or whatever substance is used in the placebo. And this has led many critics of psychiatry to suggest that even the slight superiority of antidepressants is a function of an enhanced placebo effect, rather than any specifically antidepressant property of the drugs themselves.
So here come Hieronymus et al with an interesting proposal: if the slight superiority of antidepressants is due solely to the fact that the side effects have broken the blind, then those participants who are taking the drug and not experiencing side effects should show no improvement beyond that in the placebo group.
THE STUDY
The authors examined all FDA registered double-blind trials of citalopram (Celexa) and paroxetine (Paxil) for “adult major depression” that used the Hamilton Depression Rating Scale (HDRS) to assess outcome and included an assessment at week 6. They found 15 such trials (13 for paroxetine and 2 for citalopram).
They combined the results of these 15 studies, and found that trial completers who were taking the drug and who reported no early adverse events did significantly better than completers who took the placebo. HDRS Item 1 (depressed mood) was used to assess outcome. The effect sizes were 0.49 for citalopram (a medium effect) and 0.33 for paroxetine (a small to medium effect).
The authors ran the data several ways, e.g.:
- including adverse effects during the lead-in period;
- including adverse effects during week 1 only, weeks 1 and 2 only, and weeks 1-6;
- using HDRS-17 total score, rather than just the single item depressed mood;
- etc.
The results for the various runs were largely similar, though the result with the HDRS total score was smaller: 0.38 for citalopram and 0.29 for paroxetine.
Under the heading DISCUSSION, the authors state:
“The major finding of this study is that patients treated with either paroxetine or citalopram report a larger reduction in depressed mood than those given placebo regardless of if they report adverse events or not. As such an outcome is not compatible with the theory that the beneficial effect of antidepressants is largely or solely the result of these drugs enhancing the expectation of improvement by causing side effects, our results indirectly support the notion that the two drugs under study do display genuine antidepressant effects caused by their pharmacodynamic properties.”
Note the fairly modest claim embodied in the words “indirectly support.”
and
“Two limitations of this study should be addressed. First, as it only includes data from studies regarding paroxetine or citalopram, it does not allow any conclusions regarding the possible influence of side effects on the response to other antidepressants. The observation that, for these two drugs, a clear-cut difference between groups was observed also in patients not reporting adverse events should however be sufficient to falsify the theory that all drugs regarded as antidepressants exert their action merely by means of their side effects. Second, the possibility that subtle adverse events that are recognized by the patient, but not of sufficient severity to be recorded, could influence the expectation of improvement, should not be excluded. However, the relatively low percentage of patients not reporting any early adverse events in most trials argues against side effects being under-reported.”
Actually, the percentage of participants not reporting any early adverse events was quite substantial; 23% for paroxetine and 21% for citalopram. If even half of these individuals had broken the blind through the detection of subtle unreported effects, this could significantly impact the results.
and
“In summary, although this study does not allow any firm conclusions with respect to the possible existence of a modest association between early side effects and antidepressant response for SSRIs, the results for paroxetine and citalopram being divergent in this regard, it casts serious doubt on the assumption that the superiority of antidepressants over placebo is entirely or largely due to side effects enhancing the placebo effect of the active compound by breaking the blind. We conclude that the placebo-breaking-the-blind theory has come to influence the current view on the efficacy of antidepressants to a greater extent than can be justified by available data.”
Again, note the modest claim “…casts serious doubt on…” But does it even do that? Let’s take a closer look.
DATA ACQUISTION
A meta-analysis is a study that combines the findings of several earlier studies. Because of the combined size, the findings of the meta-analysis are, other things being equal, more robust and reliable than any of the individual studies. Care has to be taken, however, to ensure that the individual studies address the issue or issues concerned, contain the data identified as pertinent, and meet certain standards of quality.
There’s something of a science to this, and almost all modern meta-analyses devote considerable attention to conducting and documenting their search protocols. In addition, almost all take the additional step of listing every individual study in the meta-analysis, so that an interested reader can pull up the originals, and examine each study’s pertinence and quality.
But Hieronymus et al didn’t do this. Here’s their account:
“We requested patient-level data regarding item-wise symptom ratings and timing of adverse events for all industry-sponsored, Food and Drug Administration-registered, placebo-controlled trials regarding adult major depression that have been conducted for fluoxetine (Eli Lilly, Indianapolis, IN, USA), sertraline (Pfizer, New York, NY, USA), paroxetine (GlaxoSmithKline (GSK), Brentford, UK) and citalopram (Lundbeck, Valby, Denmark). Lilly could not provide us with the requested information regarding fluoxetine, as these data are not available in electronic format, and Pfizer could not provide us with data regarding the timing of adverse events for the sertraline trials. GSK and Lundbeck could however provide us with the requested information regarding paroxetine and citalopram, respectively. To be eligible for inclusion, the trial should have used the Hamilton Depression Rating Scale (HDRS) for symptom rating and include an assessment at week 6. Examination of the Food and Drug Administration Approval Packages for the two drugs12–14 confirmed that we had access to all pertinent studies regarding these two drugs with the exception of two small trials, which, according to the Food and Drug Administration approval packages, were prematurely terminated: GSK/07,12 which randomized 13 patients on paroxetine (8 completers) and 12 patients on placebo (7 completers), and LB/87A,13 which randomized 17 patients on citalopram (5 completers) and 17 patients on placebo (4 completers). In addition to the Food and Drug Administration-registered trials, GSK also provided data from four post-registration trials regarding paroxetine.”
The authors report that they found 13 trials of paroxetine and two trials of citalopram that met their criteria. They listed these on Table 1, reproduced below.

Note that the trials are identified only by GSK and Lundbeck code numbers, and from this it is not possible to find the actual studies as written up, or to make any assessment as to their quality. The FDA approval packages, identified as references 12-14, were of little help. I tried to find individual studies in the FDA packages by matching the data in the above table with data in the packages, but there remained nine studies on which I could find no matches at all.
To provide some context on this matter, I searched PubMedCentral for articles with the words meta-analysis and depression in the title for the three month period June 1 2017 to August 31, 2017. I found seven articles. Six were studies, the seventh was a study proposal. All six of the actual meta-analyses listed all the studies involved. You can find the studies here, here, here, here, here, and here.
So, the question arises: why did Hieronymus et al not provide sufficient referencing for their studies to enable them to be identified and examined? The absence of this level of transparency, which has become standard in medical research, has to be seen as a major weakness.
The authors report that they were unable to include fluoxetine (Prozac) or sertraline (Zoloft) in their meta-analysis because Eli Lilly and Pfizer respectively were unable to provide the necessary data. However, a search in PubMed for studies with fluoxetine and placebo in the title yielded 204 hits; a similar search for sertraline and placebo yielded 108 hits. Surely, from these studies, Hieronymus et al could have found a sufficient number that met their inclusion criteria. Why would they confine their search to only those studies that the manufacturers could provide, when there is no shortage of studies in peer-reviewed journals? Hieronymus et al provide no explanation for this.
THE OUTCOME MEASURE
As mentioned earlier, one of the inclusion criteria for the Hieronymus et al meta-analysis was that the original study had used HDRS-17 scores to assess for improvement in the placebo and drug groups. The HDRS-17 is a clinician-administered scale based on an interview with the participant. It contains the following 17 items: depression; feelings of guilt; suicide; insomnia (early in the night); insomnia (middle of night); insomnia (early hours); work and activities; retardation; agitation; anxiety (psychic); anxiety (somatic); somatic (gastro-intestinal); somatic (general); genital symptoms; hypochondriasis; weight loss; insight. Most of the items are scored 0, 1, 2, 3, or 4. Some are scored 0, 1, or 2; others 0, 1, 2, or 3. Total score is the sum of the item scores. Highest possible score is 53. Generally a score of 0-7 is considered normal. The HDRS-17 is widely used in research, and a score of 20 or higher is usually required for participation in a clinical trial.
It is frequently argued that human emotions are too complex, subtle, and individualized to admit of this kind of numeric measurement, but that would be too wide a tangent in the present context, and so for the sake of discussion, let’s go along with the notion that the HDRS-17 measures depression. But it’s a little more subtle than that. Even a brief review of the wording of the various items reveals that the HDRS-17 was designed to measure, not those ordinary bouts of depression that we all experience from time to time, but rather “depression-the-psychiatric-illness,” specifically “major depressive disorder.” Remember, for decades it’s been a central pillar of psychiatric dogma that the despondency of “major depressive disorder” is emphatically not the ordinary bouts of the blues, but is an illness, identified by the presence of five or more “symptoms” from the DSM’s checklist of nine.
And when we examine the wording of the HDRS-17 items, we find that these so-called symptoms are reflected clearly in the HDRS-17. In that scale, we find items covering depressed mood, diminished interest in activities/work, retardation in speech and movement, agitation, etc. And when we examine the DSM’s nine-item checklist, we find that eight of these so-called symptoms are clearly reflected in the HDRS-17. So researchers who are examining the efficacy of drugs for the amelioration of “major depressive disorder” typically use the HDRS-17 Total score as their outcome measure. But Hieronymus et al use just one item from the scale: the item that assesses only depressed mood.
And — here’s the kicker — they already knew that this one item overstates the efficacy of SSRI’s. A year earlier (April 2016), three of the four authors and one other author published a paper on the efficacy of SSRI’s. In that study, which was also a meta-analysis, they calculated the effect sizes of the drug vs. placebo for each item on the HDRS-17. They found that Item 1, depressed mood, had an effect size of 0.40 (small to medium). The other 16 items had effect sizes ranging from 0.26 down to negative 0.06 (small to zero). But instead of recognizing that the drugs weren’t very effective in this regard, they cherry-picked the one scale item that exaggerated the drugs’ effects: Item 1.
In the present meta-analysis, they state:
“…only one item from the HDRS-17, depressed mood [Item 1], which was recently shown to be a more sensitive measure for detecting differences between active drug and placebo,17,18 was used as primary measure of efficacy.”
So, is Item 1 by itself a more sensitive measure, or an inflating measure of amelioration of “major depressive disorder”?
In defense of Hieronymus et al, it could be argued that they are simply presenting the drugs in the best possible light. But on the other hand, if, as pharma-psychiatry claims, major depressive disorder is a valid illness with known symptoms, and as pharma-psychiatry also claims, antidepressants ameliorate this illness by making appropriate corrections to brain chemistry, shouldn’t the drugs impact all or at least most of the symptoms? Isn’t that what happens when an illness is ameliorated? The symptoms go away. So whatever Hieronymus et al are measuring by focusing only on Item 1, it is not the composite, polythetic construction that psychiatrists call major depressive disorder.
Perhaps SSRI’s are nothing more than minimally active “happy pills” that induce a slight and temporary relief in mood in some individuals, but have no essentially salutary effects in other areas of life or in the long term? After all, cocaine is an SRI — serotonin reuptake inhibitor. Like SSRIs — selective serotonin reuptake inhibitors — it also produces a temporary mood change in some individuals, the magnitude of which, incidentally, decreases with prolonged use. But I don’t think anyone claims that it is an effective “treatment” for depression, or for anything else.
Hieronymus et al did calculate the effect sizes for the HDRS-17 total score. Here’s how they compared with Item 1:
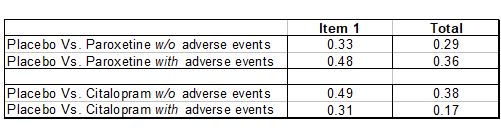
In all four comparisons, using Item 1 instead of the Total score yields an inflated effect size. Generally, an effect size of 0.2 is considered small, while 0.5 is considered medium. So using Item 1 instead of the Total score inflates the effect size from the low end of the Low to Medium range towards the high end of that range.
OUTCOME: CHANGE FROM BASELINE OR FINAL SCORE?
Most antidepressant trials that use the HDRS-17 as a measuring instrument compare the change in score for the drug participants with the change in score for the placebo group. Mean change from baseline for the drug group is compared with mean change from baseline for the placebo group. And throughout the text of their article, Hieronymus et al indicate that this is what they have done.
“Paroxetine-treated patients both with and without early adverse events outperformed those given placebo with respect to reduction in depressed mood…” (P 2)
“…with respect to HDRS-17-sum reduction…” (p 3)
“…with respect to reduction in the HDRS depressed mood…” (p 1)
“…with respect to reduction in HDRS-17-sum…” (p 3)
“The primary analyses as well as most of the sensitivity analyses suggest the ESs [effect sizes] for the reduction in depressed mood in patients not reporting adverse events to be between 0.3 and 0.5, that is, small to moderate.” (p 5)
[Emphasis added in all above]
But in the graphic display of their results, Hieronymus et al make no mention of change. For instance, here’s Figure 1.
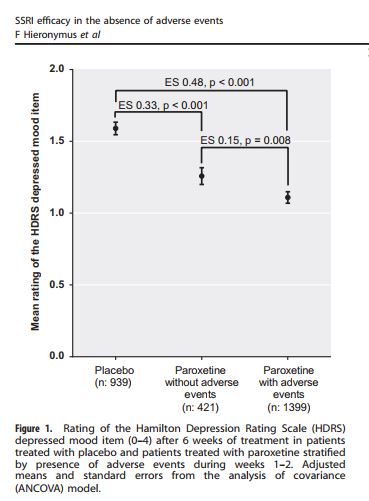
The vertical axis is labeled “Mean rating of the HDRS depressed mood item.” The “depressed mood item” is Item 1. But note there’s no mention of change or reduction from baseline. So what’s being plotted here is not mean change from baseline, but the mean score on Item 1 at week 6. So the placebo group had a score of about 1.6; the paroxetine group without adverse events, about 1.2, and the paroxetine group with adverse events about 1.1. Low scores are better than high, so both drug groups outperformed the placebo group. But this assumes that the baseline measures for the different groups were equal. Did the authors calculate the change for each individual from baseline to week 6 (by simple subtraction), calculate the group means (by dividing by the number of individuals in each group), and then compare the effect sizes for these means?; or did they just assume baseline equality, calculate the score means for each group at week 6, and calculate the effect sizes on that basis? The two methods could produce very different results. If the authors used the first method, which is the proper way to deal with this data, and is implied by the wording in their text, then why is this not reflected in the graphics they used to display their findings?
Discrepancies of this sort always arouse the concern that the authors ran the data both ways, and presented only the analysis that was more supportive of their pre-existing position. This is particularly the case when insufficient numerical data is provided to enable a reader to check these matters for him/herself.
SUBTLE EFFECTS MIGHT NOT BE REPORTED
The essential point of the article is that people who get the drugs (as opposed to the placebo) are more likely to experience side effects. This would alert them to the fact that they got the drug, and would break the blind. This in turn could engender more hope than the placebo group, and could enhance outcome. The authors found that drug participants who did not report side effects still did better than the placebo group. This, they inferred, argues against the hypothesis.
But the argument collapses if there are subtle drug-revealing effects that are not reported.
The authors recognize this possibility:
“…the possibility that subtle adverse events that are recognized by the patient, but not of sufficient severity to be recorded, could influence the expectation of improvement, should not be excluded.”
“…Should not be excluded.” In other words, the authors are acknowledging that this may be the explanation.
THE SIZE OF THE OUTCOME DIFFERENCES
Although the Hieronymus et al findings are statistically significant, they are very small when considered from a practical, human perspective. (I have discussed the difference between statistical significance and practical significance in an earlier post.)
To illustrate the magnitude of the Hieronymus et al findings, here are Figure 1 and Figure 2 from this study redrawn on a single plot.
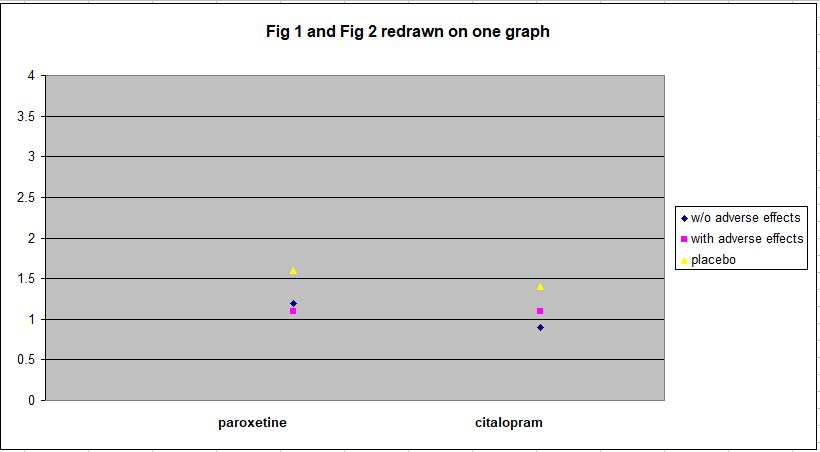
As can be seen, all the outcomes are within the range 0.9–1.6 on HDRS Item 1, which has a range of 0–4. To convey some sense of what this means in practical terms, here’s the text of Item 1:
“1. DEPRESSED MOOD (sadness, hopeless, helpless, worthless)
0 |__| Absent.
1 |__| These feeling states indicated only on questioning.
2 |__| These feeling states spontaneously reported verbally.
3 |__| Communicates feeling states non-verbally, i.e. through facial expression, posture, voice and tendency to weep.
4 |__| Patient reports virtually only these feeling states in his/her spontaneous verbal and non-verbal communication.”
The mean rating of both placebo groups at week 6 is around 1.5, i.e. about midway between a score of 1 and a score of 2. And the mean rating for the drug groups is about 1.1. A score of 1 indicates that feelings of sadness, hopelessness, helplessness, and worthlessness are expressed by the individual only in response to questioning. A score of 2 indicates that he or she expresses these feelings spontaneously.
So the drug groups, on average, consist of individuals who express this sadness only when asked, while the placebo groups, also on average, fall about midway between spontaneous expressions of sadness and reporting feelings of sadness when asked. This does not seem like a particularly large difference. And that’s when outcome is assessed using only Item 1, which has been cherry-picked to show an exaggerated effect.
The data for HDRS-17 Total Score, which Hieronymus et al present as Supplementary Figures 11 and 12, show the matter in even clearer perspective. I have redrawn this data on one plot below. The more divergent vertical scale reflects the fact that HDRS-17 Total Score has a range of 0–53, while the range for Item 1 is only 0–4.
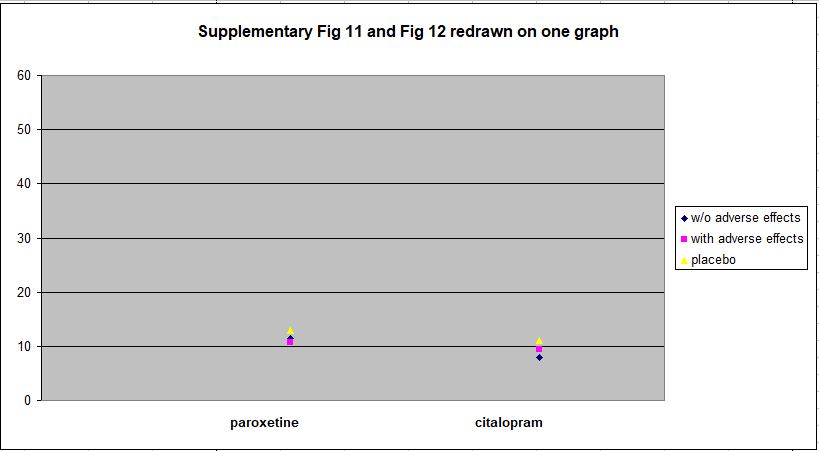
Against the full range of the HDRS-17 spectrum, the differences between the drug and placebo groups at week 6 are clearly trivial.
AUTHORS’ OWN CONCLUSIONS
As mentioned earlier, the authors’ conclusions were fairly modest and restrained:
“The finding that both paroxetine and citalopram are clearly superior to placebo also when not producing adverse events, as well as the lack of association between adverse event severity and response, argue against the theory that antidepressants outperform placebo solely or largely because of their side effects.” [Emphasis added]
Note the phrase “…argue against…” as opposed, say, to “refute” or something similar.
and
“We conclude that that the placebo-breaking-the-blind theory has come to influence the current view on the efficacy of antidepressants to a greater extent than can be justified by available data.” [Emphasis added]
Again, this sounds quite a bit short of refutation.
Nevertheless, in a Medscape.com article on August 29, 2017, Elias Eriksson, PhD, the principal author of the study, was quoted as saying:
“‘I think, once and for all, we’ve answered the SSRI question. And we have effectively rebutted the side-effects theory'” [Emphases added]
and
“‘…SSRIs work. They may not work for every patient, but they work for most patients. And it’s a pity if their use is discouraged because of newspaper reports'” [Emphasis added]
In addition, a press release from Gothenburg University dated August 18, 2017 stated:
“The researchers conclude that this study, as well as other recent reports from the same group, provides strong support for the assumption that SSRIs exert a specific antidepressant effect. They suggest that the frequent questioning of these drugs in media is unjustified and may make depressed patients refrain from effective treatment.” [Emphasis added]
Similar copy appeared in ScienceDaily, PsychCentral, MedicalXpress, and other sites.
So there’s a significant discrepancy between the authors’ published conclusions and the message delivered to, and passed on by, the media. The discrepancy is probably a reflection of the fact that it’s relatively easy to get unjustifiably extreme assertions past the media, but not so easy to get them past peer reviewers.
THE FDA, AND PARTICIPANTS’ SELF-RATING SCALES
As I mentioned earlier, I had considerable difficulty matching the studies in Hieronymus et al’s Table 1 and those in the FDA Approval Packages (reference 12; reference 13; reference14). This wasn’t from any lack of effort or enthusiasm on my part. I combed each page diligently for clues, and did find some matches, but had to give up on others.
However, in one of the packages, identified by Hieronymus as reference 13, I did find a statistician’s summary which contained the following incidental, but extremely interesting, paragraph:
“For all 11 studies, the patient-rated scales showed no efficacy or minimal efficacy. According to the medical reviewer and references provided by the sponsor, these scales have been shown to provide unreliable estimates of symptoms of depression, therefore there is little reason to be concerned about the lack of efficacy.”
So, in the eleven studies in question, the patient-rated scales showed no efficacy or minimal efficacy. Essentially this means that when the participants were asked to rate their own post-trial levels of depression, there were no significant differences between those that took the SSRI and those that took the placebo. And the FDA dismissed this as a matter of no concern, on the basis of information provided by the medical reviewer and references provided by the sponsor. The medical reviewer presumably was an FDA psychiatrist, and the sponsor, of course, was the drug’s manufacturer. The date on this document is September 1992.
I would have thought that as sadness is such an inherently personal thing, the individual’s self-reports would carry a lot of weight. But, of course, if they were showing no efficacy for the SSRI’s, I suppose they had to be dismissed. It has often been suggested that the FDA has had an overly-close relationship with the pharmaceutical companies that they are supposed to be regulating.
I wonder if self-rating scales are still ignored by the FDA today — or do trial designers even use them? Hieronymus et al made no reference to self-rating scales in the study under discussion.
THE BOTTOM LINE
This debate about the efficacy of SSRI’s has been going on for a long time and, at least in my view, the results are fairly clear: the drugs on average have little or no overall positive impact, but probably do induce small emotional changes in certain individuals. Some of the people so affected find the changes pleasant (or at least better than what they had previously); others find them unpleasant. The latter generally stop taking the drugs, though they are usually pressured considerably not to. The former group continue taking the pills, and encounter two apparently contradictory effects: they become physically dependent on the drugs, and the initial pleasant effect wears off. So they go on taking them to ward off withdrawals, which are sometimes interpreted by psychiatrists as “relapse,” and are exposed to the cumulative impact of a wide array of adverse effects.
The study that urgently needs to be done, by truly independent researchers, is a definitive examination of the role that SSRI’s are playing in the mass murders/suicides that have become a regular feature of American life. In this context, half-baked and obviously biased regurgitations of old data attempting to prove the efficacy of these drugs is the modern equivalent of fiddling while Rome burns. And incidentally, on this topic the proposal for the Hieronymus et al study, which was published a year earlier, stated that the meta-analysis “…will also be analyzing the possible suicide provoking effect of these drugs.” In fact, there is no mention of suicide in the meta-analysis. Was this an oversight? Or did Hieronymus et al find such a link and choose to suppress it?
CONFLICTS OF INTEREST
The article lists the following conflicts of interest:
“F[redrik] H[ieronymus] has received speaker’s fees from Servier. E[lias] E[riksson] has previously been on advisory boards and/or received speaker’s honoraria and/or research grants from Eli Lilly, Servier, GSK and H Lundbeck. S[taffan] N[ilsson] and A[lexander] L[isinski] declare no potential conflict of interests.”
In addition, Dr. Eriksson’s CV contains the following:
“Was a member of expert panels/advisory boards for several international pharmaceutical companies: Eli Lilly (USA), Ciba-Geigy (Switzerland), Pfizer (USA), SmithKline Beecham (England), Organon (The Netherlands), Lundbeck (Denmark), Glaxo SmithKline (UK), Rhone-Poulenc Rorer (France) and Schering (Germany). Scientific collaboration with Ciba-Geigy, Bristol-Myers Squibb, Novo Nordisk, Glaxo SmithKline, Merck, and Lundbeck.”
The CV also indicates that Dr. Eriksson has received research funding from Lundbeck and Bristol Myers Squibb.
ACKNOWLEDGEMENT
I am grateful to Janne Larsson, a Swedish investigative journalist, for drawing my attention to this study. Janne has also written an article on this matter: Big Pharma strikes back – The Ultimate Antidepressant Study, which I strongly recommend. Interestingly, this article was written in August 2016, more than a year ago, and was based on Dr. Eriksson’s proposal for the meta-analysis. Janne’s article is almost prophetic in its anticipation of the reach and content of Dr. Eriksson’s meta-analysis.














Firsties!!
U want to understand mental health challenges. Often believe U know the issues. Nobody needs to know. If u know u have it wrong.
Thats what I think of this place.
Report comment
Spamtastic!
Report comment
Ha ha! YOU are funny Uprising.
Report comment
All of the errors an weaknesses of antidepressants RCTS pale in comparison to this: almost all participants are on an SSRIs before the study. They are all stopped abruptly and given a placebo for approximately 10 days. By this time most have heavy withdrawal symptoms which will give a high depression score. Then half the group is given the SSRI being studied and the rest get to continue in cold turkey withdrawal. Anybody who gets back a drug they are in abstinence from will feel a lot better. This is the standard thing people do when they are hung over. They take another drink.
So we are no at all measuring the drug’s antidepressant effect, but just how much it decreases abstinence.
What is strange and encouraging is how well the placebo (cold turkey withdrawal) group is doing. They are hardly worse off than the drug group, and many placebo responders (those who get so much better from cold turkey withdrawal that they cannot participate in the study because they are not depressed, typically 30 %) are already removed from the study. So actually the only thing these studies show, is that a lot of people get much better from STOPPING their antidepressant, even if they do this abruptly.
Report comment
Researcher,
I agree. This is the central point. The purpose of this kind of research is not to discover any reality or truth, but rather to create an opportunity for a pharma/psychiatry-favorable press release.
Report comment
Thank you for your in-depth scientific analysis; I always appreciate truth.
The power of placebos and especially nocebos is greatly underestimated/misunderstood.
Moreover, all studies shorter than 5-10 years are predicated on the assumption that depression is a disease. Otherwise, it would be assumed that any study shorter than 5 years would be unable to assess whether outcomes were due to the effects of the drugs or a reduction of depression. Light doses of morphine can outperform “antidepressants” during most trial periods but will worsen depression significantly over time.
Report comment
Steve,
Very true. Most drug trials are ridiculously short.
Report comment
Work in What Sense?
https://www.google.co.uk/amp/s/www.bbc.co.uk/news/amp/world-europe-39877325#ampshare=http://www.bbc.com/news/world-europe-39877325
“….The family of Clodagh Hawe, who was killed along with her three children, by her husband Alan, has been speaking about the tragedy and their decision to have his body exhumed….”
“…This was not the first tragedy suffered by Clodagh’s family. Her brother, Tadhg, took his life in September 2010. Three years later, Jacqueline Connolly’s husband, Richie, also took his life…”
“…The circumstances surrounding the tragedy in 2016 will be the subject of an inquest later this year….”
https://www.google.co.uk/amp/s/amp.independent.ie/irish-news/news/alan-hawes-family-say-they-did-not-delay-exhumation-of-his-body-35701491.html#ampshare=http://www.independent.ie/irish-news/news/alan-hawes-family-say-they-did-not-delay-exhumation-of-his-body-35701491.html
“…The family were all buried together side by side in the same plot in the small graveyard in St Mary’s Church in the town of Castlerahan.
But earlier today Alan Hawe’s body was was exhumed and later cremated in Dublin…”
Report comment
Suicide Prevention in Ireland
http://www.rte.ie/news/2017/0910/903564-people-encouraged-to-offer-support-on-suicide-preventio/
I’ve had 4 suicidal hospitalizations while in treatment in Ireland in the 1980s and none since. The present day situation as regards suicide in Ireland has become a lot worse since psychotropic medications have come into common use.
Report comment
Peer support is about being the expert at not being the expert and that takes expertise. Learned that from recovery innovations training I attended in 2010.
If u live it up enough to understand it nobody has to know. If u know u had it wrong. – RF
Report comment
The good news here is that the antidepressant industry has been forced to settle for attempting to trick people into believing that their slight superiority over placebos is genuine, rather than merely due to their side effects “breaking the blind”. The bad news is that antidepressant prescriptions are still rising. Reports like yours are thus still needed to show that the antidepressant industry’s claims of marginal superiority over placebo, just like their initial claims of being miracle pills, are mere examples of fudging studies and misinterpreting/cherry-picking data in order to mislead people into believing its lies. And we need to continue bringing home the reality that these are not harmless, but are life-ruining and at times life-ending fake medications. The whole “depression is a medically treatable disease caused by a chemical imbalance” myth has been too ingrained into our culture to die easily.
Report comment
https://www.madinamerica.com/2017/03/mainstream-western-psychiatry-science-or-non-science/
This article references your main point about prescriptions rising, although I continue to see depression as biological in many cases particularly severe cases. Although this not Pat’s opinion for all people that have depression – see article.
I think depression not as much serotonin being PREVENTED from communicating with brain via central nervous system but more so a BREAKDOWN of bodily systems (for example endocrine system )which the central nervous system NEEDS to communicate with the brain.
So all in all both theories rely on a communication issue from central nervous system to brain and therefore (biological ).
Regards to previous blog on peer support – Well peer support and service to others is one of main (non mediation ) therapies for treating depression. So fabulous reason to join the expanding peer workforce.
Report comment
I think antidepressants work for some people and don’t for others, the same way drinking alcohol to relax works for some and works horribly for others.
But, till when are you people going to point out that depression is correlated with biology? The trivial fact that we are biological creatures and everything we do is related in some way to our bodies, be it laughing, crying, pooping, having sex or whatever else it is, is practically senseless in real life unless you are working to make new drugs or the like.
And “therapy” is an endless trap of listening and talking, except in a few cases. How many times have we seen “therapists” give money to people who are distressed because they lack funds? How many times have we seen them barge into abusive homes to save children from being abused? When do we ever see them risking their own neck to do anything for anyone, except sitting and talking endlessly in a closed room and keeping people trapped in “therapy” with no tangible solutions to their problems?
Nope, instead, it is an endless trap of summoning the person to the therapist’s office, making “observations” about “improvement”, sending them back solution-less to their home and waiting to do the same thing another day.
Great for the therapist’s career. Not so great for the client.
Report comment
Registeredforthissite,
Everything we do is indeed correlated with biological activity. But this in no way establishes the fact that despondency is a biological pathology. That’s the essence of the psychiatric hoax. In reality, despondency/sadness/depression is an adaptive response.
Report comment
Zoloft worked magic for me. A lot like voodoo actually. A kind, compassionate nurse talked to me while I wept uncontrollably from guilt for wanting to kill myself. I feared I would go to Hell.
For over a year I had almost no one say ANYTHING kind to me. I was mentally ill, so taking “meds” was all I needed. Forget kindness or empathy. Those are for “normal” people, but the SMI can live without any compassion. We have no emotional needs at all–except those cocktails can control.
The nurse’s kind words inspired the placebo effect and ended my depression in less than 12 hours. No 30 day waiting period required.
Too bad I had to go to the hospital and take drugs to have someone talk to me nicely.
Report comment
Several factors are involved in the continuing increase in anti-depressant use.
1. The constant advertising of medication – if you `suffer’ ??? see your doctor and take a pill. This perpetuation of magical powers of `medicine’ that got its main push with Penicillin, a truly magical drug, in the 1940s.
2. The expectation that life should be pain free
3. The belief that doctors are miracle workers and will make life pain free
4 The lack of training of first level doctors, particularly in mental health. (approx 40 hours total)
5. Time pressure in first level doctors
6. Drug companies direct advertising to doctors, including quasi bribery.
7. Refusal of government authorities to examine drug trial results, cause, ? bribery.
I’ve probably left some out, but you see the picture. The application of the name `anti-depressant’ to drugs that are essentially tranquillisers, and to attach them to a fake process (the`chemical imbalance’) was arguably the greatest advertising/marketing/PR stunt in history, except possibly, `the Jews did it’ and `God is love’. Breaking the false belief of an entire generation could take as long as removing a religion.
Report comment
Deeeo42,
Don’t forget “free” screenings for depression!
Report comment
Yeah, everyone is attracted for something `free’ – but really nothing is. The organisations that offer these `freebies’ are actually recruiting customers and profiting as a result. That way they justify their existence.
Way to go – the incidence of manic depression, rare in my days in the mental `health’ business, is now, 5%? In a generation? Some of that increase is, of course one of the effects of these very drugs SSRIs. What a bonanza! First give someone a drug that causes the symptoms of another illness, then give them more drugs to treat that illness, for LIFE, because they now have a `chronic’ incurable severe mental `illness’ – Again, way to go.
A thought, was that a happy accident or did they do it on purpose?
The rest is the gathering of a bunch of normal behaviours and calling them pathological. A pathology that can only be controlled by drugs and shock for all of life!
How sad that one of the richest, most exciting times in all of history, is being trashed for money, but then, I guess that was always the way for the peasants, i.e. most of us.
Report comment
You don’t see a bunch of commercials for penicillin, nitro-glycerin, or–Big Pharma’s favorite analogy–insulin for diabetes.
Most money makers for pharmaceutical companies seem to be mind altering drugs. A lot of my friends and family never would have taken these drugs had they not been fed the chemical imbalance myth.
Report comment
Lawrence,
Very true. It’s become “common knowledge”!
Report comment
It’s very seductive. If you have a “disease” you don’t have to do squat, but take pills and sit on your duff.
I benefited from Zoloft because a nurse spoke kindly to me before giving me the pill. It was the first time in almost a year I had heard one kind word. Seriously.
If someone had spoken kindly beforehand I might not have wound up there in the first place.
Report comment
My studies lend that medicines work better for schizophrenia in more cases then they do for depression.
I have schizophrenia and it turns out that There are actually three causes of schizophrenia. One is firing if neurotransmitters within central nervous system bring out of whack. (Medicine works – allieviates here).
The additional two are hormone regulation and functioning of the endocrine bodily system and third an environmental trigger such as a history of trauma.
Knowing that a psychotropic alters the function of neurotransmitters The medicine for other two causes may make not work for better.
My studying for those that have depression is that the cause is more of breakdown of bodily system (such as endocrine) that the central nervous system needs to communicate with brain as opposed to serotonin being prevented from going to brain.
Those two theories have some similarities but vastly different. Are the depression medications actually working with neurotransmitters the way needed? I think no actually. It may be a bit different to many of you in trained in medical field.
So my studying leads me to think that medicines work better for schizophrenia In most cases then they do for depression it turns out.
This is because the medicine is targeting correct function sometimes in schizophrenia but not really that much with depression.
Report comment
Good for you, schizophrenic.
Not everyone would want to have that ghastly truth-obfuscating label attached to their name.
So what if you have labelled something as “schizophrenia” or “major depressive disorder” or “bipolar disorder”?
Specify what you are talking about explicitly.
Report comment
PatH1980,
Firstly, there is no evidence that “schizophrenia” is caused by neural pathology. Secondly, there are some relatively rare instances where depression is caused by a biological pathology, but the vast majority of depression is attributable to loss, and/or adverse circumstances, and/or counterproductive habits.
Report comment
Philip,
What are the causes of depression in the rare cases in which a biological pathology is in play? I’d just like to be more informed about this for future conversations. Thanks.
Report comment
Anemia and low thyroxin levels often bring on depression for me.
Report comment
Uprising,
Probably the best reference for this is, ironically, the DSM itself. DSM-5 has a category called “Depressive Disorder Due to Another Medical Condition”. One of the criteria is:
“B. There is evidence from the history, physical examination, or laboratory findings that the disturbance is the direct pathophysiological consequence of another medical condition.” (p 180)
Here are two quotes from the text:
“In determining whether the mood disturbance is due to a general medical condition, the clinician must first establish the presence of a general medical condition. Further, the clinician must establish that the mood disturbance is etiologically related to the general medical condition through a physiological mechanism.” (p 181)
“Etiology (i.e., a causal relationship to another medical condition based on best clinical evidence) is the key variable in depressive disorder due to another medical condition. The listing of the medical conditions that are said to be able to induce major depression is never complete, and the clinician’s best judgment is the essence of this diagnosis.
There are clear associations, as well as some neuroanatomical correlates, of depression with stroke, Huntington’s disease, Parkinson’s disease, and traumatic brain injury. Among the neuroendocrine conditions most closely associated with depression are Cushing’s disease and hypothyroidism. There are numerous other conditions thought to be associated with depression, such as multiple sclerosis. However, the literature’s support for a causal association is greater with some conditions, such as Parkinson’s disease and Huntington’s disease, than with others…” (p 181)
So, as you can see, it’s a bit vague. Of course, all serious illness can precipitate feelings of sadness and despondency, but the issue here is that the illness produces the feelings of sadness through a direct physiological mechanism. And, of course, this mechanism itself isn’t fully understood, so there will always be disagreement in this area.
Report comment
Damn… I guess my supposition wasn’t written that well. I worked hard on that. Next time I’ll be more clear and succinct.
I was going over my studies and although not certain mentioning that medicines work better for schizophrenia in more cases then they do for depression.
Report comment
Comment removed for moderation
Report comment
You’re in a league of your own. That’s for sure.
Report comment
Intimidated? Seriously? I have given you plenty of coherent replies. The most relevant here is the question you were already asked: if some cases of depression/psychosis are caused by biology alone, how specifically do you distinguish which cases are or are not? Drug response is not an adequate answer, not even close – all of these drugs have similar effects of those diagnosed vs. not diagnosed. Just like alcohol relaxes most and removes inhibitions, these drugs have effects on people’s brains that are not specific to a “disorder.” Until you can sort out the conundrum of diagnosing which people have which condition, your theories remain theoretical.
You also appear to forget that while the best correlation with genes and any “mental disorder” is about 15%, the correlation with trauma is more like 85%. Which seems more likely to be the relevant causal factor?
Please knock off the insults. They diminish the credibility of your presentation.
Report comment
Hey, why was his comment “removed for moderation”?
All he said was “my position is superior to so-and-so person and you guys are intimated [sic] by it”.
It was funny more than insulting.
Report comment
I agree. 🙂
Report comment
Steve,
Thanks for this.
Report comment
You’re welcome, and thanks for the positive feedback!
Report comment
Hi Phil,
Thanks for taking the time to do this.
The take-home piece for me was:
“Against the full range of the HDRS-17 spectrum, the differences between the drug and placebo groups at week 6 are clearly trivial.”
This is what I expected from when I began reading your article. When you have a forty point scale, and the difference between taking a drug or a sugar pill might (or not) at most be a point or two over several weeks, does it really even matter which one you are taking or not taking? (well, it can, due to other antidepressant adverse effects, but that’s another story).
The big picture is that what is going on or not going on in people’s lives / social environments is so much more important when it comes to affecting their mood than whether they are taking a “real” antidepressant or not. But to acknowledge that could lead to the loss of billions of dollars in profits.
Of course, the real unacknowledged goal of these pieces is to promote the self-interest of both the authors and the drug companies, which are much the same…
Report comment
Matt,
Yes. Which is why the press releases always say more than the studies. And people remember the press releases.
Report comment
Much of this study and ensuing discussion require the implicit acceptance of false premises as the price of admission: e.g. the idea that there is an individually-based “condition” which needs to be forcibly alleviated, i.e. the unpleasantness which results from reacting to the cumulative dehumanization of one’s lifetime. This is a political position based on an assumption that the ruling system and its officially approved lifestyles are a given, and that failing to get with the program is a failing of the individual, not the system.
A corollary to this observation would be that seemingly “positive” states of thought and behavior evoked on occasion by the ingestion of psychotoxins are not “real” and, at best, temporarily mimic those which would accompany genuine well-being. To compare real feelings with drug-induced ones is absurd. “Better” for whom should be the real question.
Report comment
Oldhead,
Good points. When we compare our evolutionary origins with the lives that most people live today, we are like fish out of water. Depression is our bodies screaming at us to make some changes!
Report comment
Well this site reviews studies. Although signifiant I proposed a genuine and alternate theory to work from. In turn I solved riddle as to how severe major depression tends to recur throughout life.
Could this also be reason benzos come into picture so often with having depression and anxiety?
Are u all so against viewing above supposition because its biological and dismiss it entirely?
Report comment
Not sure I understand what your supposition is?
Report comment
I didn’t see ur above reply so here I go.
Supposition is that medicines work better for schizophrenia in more cases then they do for depression.
Ur question is: if some cases of depression/psychosis are caused by biology alone, how specifically do you distinguish which cases are or are not?
Pat response is: U can’t sort it out and that is what makes psychology its own unique soft science. In addition If u live it enough to understand how bad it hurts nobody has to know or sort out. If u know u had it wrong. U use what helps.
I personally think service to others and peer support help a lot of people that have depression. I also promote reading spiritual books whatever ur denomination is or self help for those agnostic. Actuall for those are agnostic I might suggest philosophy for much better than self help I think.Person could move from Nietzke to Kierkagaard. Ah what a gift for me and done from persons own volition.
Report comment
There is no “schizophrenia”. Are you talking about people who are psychotic?
Report comment
“Schizophrenia” is as real as the constellation Orion, but no more so. Paula Caplan gave this analogy in her book They Call You Crazy. This would make psychiatry comparable to astrology rather than astronomy.
Report comment
It doesn’t sound like we disagree much, except on terminology. I have never been opposed to people choosing to try drugs if they seem to work for them. I am opposed to psychiatrists lying about what they know and pretending that all cases of “mental illness” are caused by faulty brain chemistry or wiring or and that the drugs are specific “treatments” for specific “conditions” which they supposedly understand. Beyond that point, we seem to be in agreement on each person needing their own approach. “You use what helps.”
As for science, I’m afraid the inability to make a distinction between who “has” and “doesn’t have” “schizophrenia” makes any kind of scientific conclusions absolutely impossible. The first job of science is to distinguish an experimental group from a control group. If we are unable to consistently parse these two groups, any scientific conclusion is meaningless.
For instance, let’s say that 10% of cases of “ADHD” are due to low iron (a known cause of “ADHD” symptoms). If we treat 100% of “ADHD”-labeled kids with iron, only 10% get better. If you compare this treatment to stimulants, which at least temporarily reduce symptoms in 70% or so, stimulants look like the better “treatment,” even though there is no specific understanding of what is being “treated” and even though people without “ADHD” diagnoses react to the drugs in the same way.
So we conclude (erroneously) that stimulants are a better “treatment for ADHD” than iron, even though 10% of subjects would be cured by being given iron alone. The 10% should not be diagnosed with ADHD, they should be diagnosed with iron deficiency.
So you see, if you can’t properly divide your participants into objectively discernible groups, your research leads to meaningless or misleading results. If you grouped them into “hyperactive – low iron” and “hyperactive – normal iron”, you’d have gotten 100% success, but when you call it “ADHD,” 10% of your population never gets the help they really need.
Hope that makes sense!
Report comment
A psychiatrist would point out that people are indeed screened for nutritional deficiencies.
Report comment
A psychiatrist would point out that people are indeed screened for nutritional deficiencies.
I was a psychiatric “patient” for 15 years and I was screened exactly zero times for nutrient deficiencies.
Report comment
@uprising:
Interesting and deplorable. I was screened for nutritional factors. That doesn’t preclude the rest of the disgusting crap that came along (despite their best intentions) with psychiatry though.
Report comment
Uprising’s right. Psych patients seldom get nutritional screenings, and they’re likely to get fewer, because the dreaded orthomolecular shrinks do them regularly, which forces the orthodox to shun such wicked quackery by reflex.
Report comment
The many psych patients I worked with (mostly foster youth) were not even screened for CURRENT stress and trauma. None were EVER screened for nutritional issues nor were 98% even screened for physical conditions that might lead to their symptoms. All the psychiatrists were primarily interested in was a list of symptoms and their severity so they could decide what drug to prescribe.
Report comment
Absolutely and exposes the enormous gap between psychiatric “science” and genuine science. Unfortunately most people don’t know the tenets of real science, just the words” scientifically proven” sell the idea as well as the product. Hence the enormous sales of relatively useless “alternatives”. For instance, A friend who has just been diagnosed with cancer, and who has been involved in a lot of research into psych drugs, has approached cancer treatment with the same vigour and is finding a very similar picture. The `real’ i.e. establishment ones are extremely toxic with, for her cancer, very poor results, and she has been pointed towards at least 4 other very expensive `alternative’ programs whose research is slim to put it mildly.
What is happening in medicine today?
`Do we want to believe in a “magical” treatment for our worst times? Is the generalized loss of “God” being displaced onto the “doctor” to cure us all with pills, or worse? This then places a huge burden on the doctor because he/she is not God and therefore cannot make us better, but must try. After all he/she belongs to the same beliefs as everybody else in our society. As a “healer” the doctor places a huge expectation on him/herself therefore forever pushing more and more extremes of treatments. Needless to say the more ephemeral “illnesses” will attract the “furore therapeuticus” making it possible for even the most benign and gentle ”healers” to do terrible things in order to “help”. From there the path is not going to be very good for the “sick” person. Nonetheless, aren’t we all complicit.’
And there are always plenty of those who will make money where they can regardless of the misery they cause.
Report comment
Steve,
That is indeed the key. The entire purpose of the DSM is to legitimize the drug pushing.
Report comment
Yes it does and it will continue to do so unless the individual tries to find out why. Drugs do not treat the `why’.
Report comment
PatH1980,
I certainly don’t dismiss biology. But psychiatry’s notion that every significant problem of thinking, feeling, and/or behaving stems from biological pathology is a hoax. Pure and simple.
Report comment
I find it amazing how many conservative church-goers buy into the idea that all our thoughts, feelings, and moral choices stem solely from brain chemistry. Or maybe this only applies to the mad, who are soulless monsters after all.
When slave-owners were major contributors to church coffers and ran communities, people believed in partial evolution. God made a white Adam and Eve in His own image from the dust of the earth. But the black, and perhaps yellow peoples evolved from apes. “Normal” people are free moral agents, fully ensouled. “Science” has proven that the SMI have no souls!
Report comment
Remember, Phil, the DSM-5 is nothing more than a catalog of billing codes. ALL of the so-called “diagnoses” in it were invented, and NONE were “discovered”.
Do you see what I did there, with the distinction between “discovered” and “invented”?
And BTW, that HDRS is a 100% subjective reporting form for subjective responses as related by anecdote. In other words, the HDRS *itself* is arbitrary and subjective. So, they’re using an arbitrary and subjective scale to measure *something*, – what people SAY, about how they FEEL. There’s no room in the HDRS for ANY medical, lab, blood tests, etc., See what I mean? You can word it better than I can….
Report comment
Ok I’ll come forth. These are not my theories. They were already written by my hero who I won’t mention. I’ll make you work for it you concur with my supposition.
Really all I did was compile his work and mad in America articles and a couple of my ideas and fill in the rest. This wouldn’t be my social work thesis anyway as I’m considering applying to graduate school.
Report comment
Good luck! Maybe you can apply for a Lilly scholarship. I think they may still have one, but because they insist their applicants attend classes AND take drugs I’m not sure how many success stories they have.
If I ran a brewery could I award a scholarship to fraternity/sorority members who got drunk every evening?
Report comment
You know what!! Pharma has made me rethink how to do experiments entirely. The next time I do an experimentation on gravity. I’m going to blow away the competition. I am going to state the laws, you know Sum of the forces, F=ma crap, and I’m just going to ask the object, be it ball, rock or whatever, “So tell me, did you feel a force close to 32.2 ft/sec^2 or 9.81 m/sec^2 as I dropped you?” That’ll do it. My correlation will be SO near to one!
It will be spectacular. I’ve got to sell this! I’m a genius. I’ll change engineering as we know it. What do you know? I think I’ll apply to NASA. I’m gonna be rich!
What do ya think?
Haven’t they figured out that putting lipstick on a pig; it’s still a pig. And unless they can state some correlation between some measurement of serotonin and depression. It ain’t gonna work. Oh that’s right, we don’t need to state what we’re testing in the abstract. We don’t have to use the scientific method. Why bother?
Report comment
Anonymous2016,
Nice!
Report comment
You need to work on your PR and marketing. After that you can declare yourself a real scientist and get prestigious grants and awards.
Report comment
http://www.coventrytelegraph.net/news/coventry-news/nuneaton-boy-school-shotgun-jailed-13591686
“…Jailing the youngster, His Honour Judge Andrew Lockhart QC said: “This is a dark day for you.
“It’s plain to me that this was outside the character you have exhibited your whole life.
“I now accept that in the run-up to this deed you had been suffering from severe depression and felt yourself to be hopeless. You should have shared that with your parents or anyone else…”
http://www.dailymail.co.uk/health/article-4726134/Can-pills-depression-turn-killer.html
“…David has always believed that his psychosis was caused by a type of antidepressant known as a selective serotonin re-uptake inhibitor (SSRI) ..”
http://www.thepillthatsteals.com
“…The Pill That Steals Lives, One Woman’s Terrifying Journey To Discover The Truth about Antidepressants, by Katinka Blackford Newman is published by John Blake Books, £8.99, Available UK bookshops, Amazon and in most countries.
The research from her book has prompted a 1 hour BBC Panorama Special that investigates whether an antidepressant could be the cause of one of the worst mass killings of this century. It is due to air on 26 July at 9 pm. …”
Report comment
They certainly stole mine – 2 weeks on Prozac, (for stress!) with an acute suicidal reaction got me 87 ECT treatments and 13 years of umpteen drugs for a non-existent bipolar diagnosis. It killed my career as a writer, and sculptor, both of which were burgeoning at the time, stone dead, and left me on welfare.
Report comment
Mine was more like 20. It was rough on my loved ones too. At least I never murdered anyone. Some people, apparently have gone that crazy on SSRI drugs.
Report comment
They do say that psychiatry is to medicine what astrology os to astronomy.
Report comment
Wrong. Astrology has several thousand years history behind it.
Psychiatry is 21st Century Phrenology, with potent neuro-toxins.
Astrology has far more credibility that psychiatry can EVER have!
>LOL<
Psychiatry DOES call its' DRUGS "medicines", and "meds", but that's about all
it has in common with actual Medicine.
*not*LOL*….
Report comment
Thanks for this Philip. Here are other flaws in the study to consider. The study authors state:
“Second, the possibility that subtle adverse events that are recognized by the patient, but not of sufficient severity to be recorded, could influence the expectation of improvement, should not be excluded. However, the relatively low percentage of patients not reporting any early adverse events in most trials argues against side effects being under-reported.”
Their conclusion is meaningless. It doesn’t matter what percentage of patients don’t report side effects because ALL of the patients in their first comparison group are in this category. As the authors correctly suggest, just because a patient does not report common side effects does not mean that they do not detect effects of the drug. If they detect effects of the drug, then the double blind is broken. So the part of their article that equated patients not reporting side effects with their not knowing they were receiving the drug has no validity because they did not address the question they claim to be addressing (Do patients receiving SSRI’s benefit from the placebo effect through detecting that they are receiving the active treatment?)
The second conclusion, that side effect severity is not correlated with impact of any apparent benefit of the drug, also fails to actually address the researchers’ question. Note that the ratings were done by the psychiatrists (not the patients) so the psychiatrist being blind to whether or not the patient was receiving the drug is the crucial part of the double-blind. However, as soon as the patient reports a common side effect, then the blind is broken; the psychiatrist now knows the patient is receiving the drug. It doesn’t matter if the patient reports two or ten side effects or whether they are mild or severe. If you touch my toe I will know it, and touching it harder won’t make me know it any more. So suggesting that we should expect a stronger placebo effect if the reported side effects are stronger makes little sense. The double blind will be broken for both patient and psychiatrist with only one common mild side effect.
The greatest travesty of this article, however, is not what it reports but what it cannot report. The question that the authors purport to answer is fairly easy to address. It would be simple for the FDA to conduct a double-blind study in which both patients and their psychiatrists are asked to “guess” whether the patient is receiving the drug or a placebo. Their confidence in this guess can also be assessed, and done repeatedly throughout the course of the study. If we had this data then WE wouldn’t have to guess about whether the double blind has been broken, or come up with the ridiculous post-hoc analyses that these authors did. In addition, within this same study two placebo groups can be used, one using an “inert” placebo like sugar, and the other an active placebo that has a noticeable effect on the body (e.g. caffeine). The active placebo is more likely to lead patients to believe that they have received the medication, so makes for a more fair and blind comparison. These ideas will not be new to people in the field. The fact that it would be easy to do, yet has not yet been done, while we continue to medicate many millions of people with potentially fatal consequences; that is a travesty.
Report comment
in fact such studies have been done – The Emperor’s New Drugs: Exploding the Anti-depressant Myth – Irving Kirsch 2011 – The Myth of the Chemical Cure – Joanna Moncrieff 2008 – Deadly Psychiatry and Organised Denial – Peter Goetzsche 2015 – Interesting how more and more studies like this are being done is spite of the existence of those that expose the anti-depressants as neurotoxic substances that really only do harm. I guess these guys have to justify their grants somehow, and big pharma’s profits must be protected no matter the misery their products continue to cause.
Report comment
Geoffrey,
I agree. In psychiatry, the really important studies never get done!
Report comment
I’d like to know why the Hamilton scale was used for so many paroxetine studies and so few citalopram studies. Does a preliminary, undocumented assessment of score changes wrought by particular antidepressants steer drug companies toward a particular test for each drug?
Report comment
BetterLife,
Your suggestion is certainly plausible – note the FDA admission that they routinely ignored self-rating scales that show the drugs in a poor light. But I don’t know if there’s something similar going on with the Hamilton. It could simply be that Lundbeck did fewer trials on citalopram than GSK did on paroxetine. Or perhaps some citalopram trials were rejected by Hieronymus et al for failure to meet other criteria; e.g., no assessment at week 6; no separate assessment of item 1; no assessment of side effects during weeks 1-2.
Report comment
I was just trying to fathom what this study was trying to say only last week, because its still used as a primary defence for antidepressants, so it was great to see that someone had managed to work it out.
Cherry picking the mood item is a key tactic employed, along side the subset theory (some people have properties that make them benefit a lot – and presumably some people are the opposite and greatly harmed).
Interestingly, the Cipriani review of Feb 2018 had an effect size of just 0.24 for citalopram on the 53 point Hamilton.
Report comment
ConcernedCarer,
Thanks for coming in, and for your words of encouragement.
Best wishes.
Report comment
Going back – the DSM’s position on `other medical causes of depression’, e.g. anaemia, ow thyroid, traumatic brain injury etc. A massive irony isn’t it, that psychiatrists treat depression by CAUSING a Traumatic Brain Injury (TBI) by electrocuting the brain!
Report comment